An Introduction to Amazon SageMaker Python SDK11 Apr 2025 | 6 min read Sagemaker Python SDK on AWSThe suggested library for creating solutions is the Sagemaker Python SDK from Amazon. The AWS web portal, Boto3, and the CLI are the other methods to communicate with Sagemaker. The SDK ought to provide the greatest developer experience in principle, however I found that there is a learning curve to get started right away. This article demonstrates the key SDK APIs using a straightforward regression task. Regression Task: Predicting Fuel ConsumptionI selected a regression task broke down the problem into three stages:
Storing artifacts in S3 ensures they can be reused, shared, or deployed conveniently. Sagemaker Preparation and InstructionS3 and Docker containers are the two dominant components in Sagemaker. S3 serves as both the export destination for training artefacts such as models and the primary storage repository for training data. Preprocessors and Estimators are the core interfaces for preprocessing data and training models that are provided by the SDK. All these two APIs are are Sagemaker Docker container wrappers. When a preprocessing task is generated using a Preprocessor or a training job is created using an Estimator, the following occurs internally:
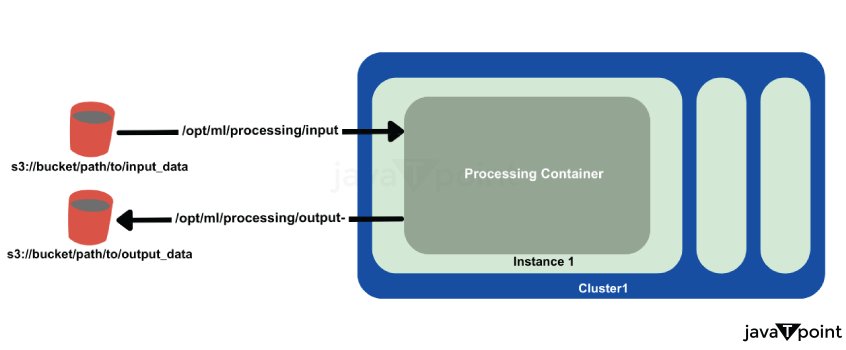 SageMaker Preprocessing ContainerData transfer to and from a preprocessing container is illustrated below. SageMaker Containers Familiarity with environmental variables and predefined path locations in SageMaker containers is crucial. Key paths inside the container include:
Project Folder StructureThe diagram below depicts the project folder structure. The main script is the Python notebook auto_mpg_prediction.ipynb, whose cells are executed in SageMaker Studio. Training and preprocessing scripts are found in the scripts folder. Initial ActionsFirst, let's initialise a SageMaker session and then do the boilerplate procedures required to acquire the default bucket, execution role, and region. Prefixes are also made for important S3 locations so that data can be stored there and preprocessed features and models can be exported. Output: Region: us-west-2 Bucket: <bucket-name> Role: arn:aws:iam::123456789012:role/service-role/AmazonSageMaker-ExecutionRole Explanation: In order to perform SageMaker operations, this code initialises a SageMaker session and gets necessary configuration information, including the AWS region, default S3 bucket, and IAM execution role. It specifies the routes in S3 for storing both raw and preprocessed data, and it offers the assistance function get_s3_path() to create complete S3 URLs on the fly. The seamless connection between SageMaker, S3, and other AWS services is ensured by this configuration. Transfer of Raw Data to S3The next step is to move our raw data to S3. An ETL operation usually specifies an S3 bucket as the final data destination in a production environment. The function that gets the raw data, divides it into test, validation, and training sets, and then uploads each set to the appropriate S3 URL in the default bucket is shown below. Output: Uploaded train.csv to s3://<bucket-name>/auto_mpg/data/bronze/train/ Uploaded val.csv to s3://<bucket-name>/auto_mpg/data/bronze/val/ Uploaded test.csv to s3://<bucket-name>/auto_mpg/data/bronze/test/ Explanation: Using the specified session and bucket locations, this function downloads the MPG dataset, splits it using a train-validation-test methodology, and publishes each split to S3. To effectively manage space, it removes the local files after uploading. Stage 1: Feature EngineeringThe preprocessing steps are implemented using the Scikit-learn library. This stage aims to:
The SageMaker Python SDK offers Scikit-learn Preprocessors and PySpark Preprocessors, both of which come with Scikit-learn and PySpark pre-installed. However, I found it impossible to use custom scripts or dependencies with both, which led me to utilize the Framework Preprocessor. To instantiate the Framework Preprocessor with the Scikit-learn library, I provided the Scikit-learn estimator class to the estimator_cls parameter. The .run method of the preprocessor includes a code parameter for specifying the entry-point script and a source_dir parameter for indicating the directory containing all custom scripts. Be attentive to how data is transferred into and exported from the preprocessing container using ProcessingInput and ProcessingOutput APIs. The container (/opt/ml/*) and S3 paths for data transfer are specified here. Note that unlike Estimators that are executed with a .fit method, Preprocessors use a .run method. Output: Job started. Path to preprocessed train features: s3://<bucket-name>/auto_mpg/data/gold/train/train_features.npy Path to saved preprocessor model: s3://<bucket-name>/auto_mpg/models/preprocessor/preprocessor-<timestamp>.joblib Explanation: Using a Scikit-learn container, this code initialises a SageMaker FrameworkProcessor to do a customised preprocessing job. It imports the unprocessed data from S3 into the container, runs the script on it, and then outputs the model artefacts and preprocessed features back to S3. Stage 2: Model TrainingThe training process is similar to the preprocessing step, utilizing the Estimator class from the SDK. I decided to use the XGBoost algorithm for the regression task. Training the Model This example focuses on hyperparameter tuning for the XGBoost algorithm. After defining the hyperparameters, we can instantiate the XGBoost estimator and proceed with model training. Output: Training complete! Model artifacts can be found at: s3://<bucket-name>/auto_mpg/models/ml/xgboost-<timestamp>/output/model.tar.gz Explanation: Using the role, instance type, output path, source directory, training script, and hyperparameters, the code initialises an XGBoost estimator in SageMaker. Next, it uses S3's preprocessed data to train the model. The trained model is saved to the designated S3 storage after it is finished. Stage 3: Model InferenceTo test our trained model, we'll invoke a SageMaker predictor, which sends requests to the inference endpoint using the provided test data. Output: Predictions: [21.5, 19.2, 24.3, ...] Explanation: For real-time predictions, this code calls the "xgboost-endpoint" endpoint using a SageMaker Predictor. The input data is sent serialised as CSV, and the expected values, like [21.5, 19.2, 24.3,...], are printed. Next TopicAn-introduction-to-rocketry-in-python |
Subscribe to Tpoint Tech
We request you to subscribe our newsletter for upcoming updates.
We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
Contact info
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
Follow us
