No More ETL: How Lakebase Combines OLTP, Analytics in One Platform
Databricks Lakebase is a serverless Postgres database unifying real-time transactions and analytics for modern apps and AI—no ETL or infra hassle.
Join the DZone community and get the full member experience.
Join For FreeDatabricks' Lakebase, launched in June 2025, is a serverless Postgres database purpose-built to support modern operational applications and AI workloads—all within the Lakehouse architecture. It stands apart from legacy OLTP systems by unifying real-time transactions and lakehouse-native analytics, all without complex provisioning or data pipelines.
Under the hood, Lakebase is PostgreSQL-compatible, which means developers can use existing tools like psql, SQLAlchemy, and pgAdmin, as well as familiar extensions like PostGIS for spatial data and pgvector for embedding-based similarity search—a growing requirement for AI-native applications. It combines the familiarity of Postgres with advanced capabilities powered by Databricks' unified platform.
The system is also serverless by default, providing automatic scaling, compute-storage separation, and zero-copy branching, allowing dev/test environments to be spun up instantly without duplicating data. For organizations looking to simplify their data stack while preparing for the demands of AI and high-volume workloads, Lakebase is a compelling evolution.
Why Does Lakebase Matter?
Modern enterprises demand systems that support:
- Real-time decision-making
- AI-driven personalization and automation
- Data consistency and security across functions
- Scalability without infrastructure bottlenecks
Yet most companies still maintain two separate data stacks:
- An OLTP database (like Amazon RDS, MySQL, or Postgres) that handles day-to-day transactions.
- An OLAP system (like Redshift, Snowflake, or BigQuery) to run analytics and ML workloads—often with hours or days of lag due to ETL delays.
This disjointed approach leads to inefficiencies:
- Software engineers are focused on building transactional APIs but remain constrained by data sync delays and testing limitations. From a Software Engineers perspective, not manage pipelines or worry about stale data in the analytics layer. If the same system that records transactions can feed dashboards and models in real-time, that’s a massive unlock.
- Data engineers must own complex ETL pipelines, orchestration, schema transformations, and backfills—adding operational burden. Typically Data Engineers spend hours managing DAGs, fixing schema mismatches, and debugging ETL failures. Lakebase short-circuits all that by making transactional data instantly available in Delta format
- ML engineers wait for "fresh-enough" data to serve accurate predictions, or are forced to build parallel pipelines for feature extraction.
OLAP Management Overhead
In traditional data engineering setups, significant management overhead arises from responsibilities extending far beyond simply extracting and transforming data from OLTP databases. Data engineers must meticulously manage downstream systems, such as data warehouses or lakehouses, ensuring consistency, governance, and continuous availability. They face several persistent challenges, including maintaining ETL pipeline integrity through regular script updates, job scheduling, robust failure recovery processes, and careful management of pipeline dependencies. Additionally, traditional ETL processes often lead to latency issues, resulting in analytics data being several hours behind real-time events. When data corrections or schema changes require backfills, the performance of analytics platforms can degrade substantially, disrupting business insights. Moreover, maintaining separate schemas for OLTP and OLAP layers introduces governance complexity, creating access control silos and making lineage tracking cumbersome. Furthermore, provisioning safe development and testing environments frequently requires extensive cloning of full databases, resulting in significant time investment and increased operational costs.
With Lakebase, many of these overhead challenges are either entirely eliminated or greatly reduced. Transactional data is immediately available in Delta format, rendering traditional ETL pipelines obsolete and ensuring real-time data freshness. Centralized governance provided through Unity Catalog simplifies the management of security, enabling seamless implementation of row-level security, comprehensive lineage tracking, and detailed audit logging. Development branches leverage zero-copy cloning technology, facilitating rapid and cost-efficient environment provisioning. As a result, Lakebase significantly reduces administrative complexity, accelerates data availability, and enhances overall operational efficiency.
How Lakebase Works (With a Real Use Case)
Let’s illustrate how Lakebase functions with a practical use case: an e-commerce order management system.
Traditional Flow
In a typical system:
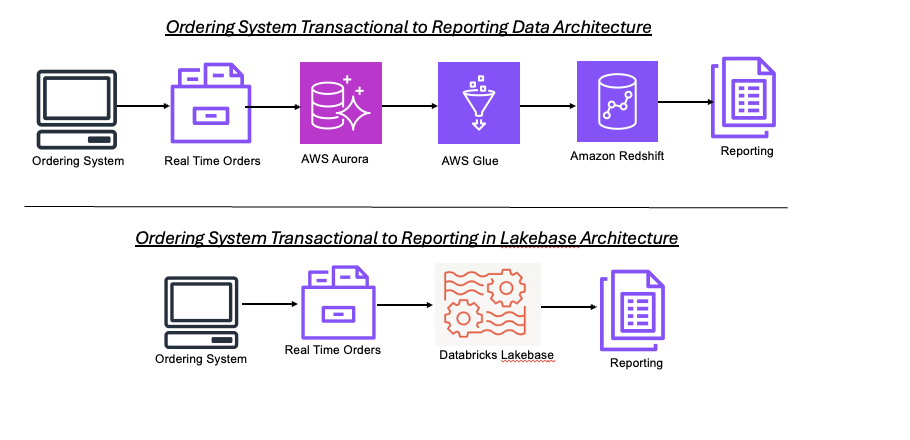
- Orders are stored in Amazon RDS (Postgres).
- Data engineers extract order records to S3, then transform them using AWS Glue, and load into Redshift for BI and ML.
- AI models (e.g., for fraud detection) use delayed snapshots or materialized features.
- QA and dev teams struggle to test discount or pricing logic without staging environments that mirror production.
With Lakebase
1. Real-Time Orders and Transactions
A customer places an order on the website. The frontend application makes an API call to a backend service that inserts the order into Lakebase via Postgres-compatible drivers.
- Transactions are ACID-compliant
- Latency is sub-10ms
- The data is immediately visible across all Databricks tools
2. No ETL, Just Fresh Data
As data is written to Lakebase, it's automatically synchronized as Delta Tables. This eliminates the need for extract/load jobs.
- BI dashboards built with Power BI, QuickSight, or Databricks SQL reflect up-to-date order data.
- Data scientists can query the order table seconds after creation, enabling true real-time analytics.
3. AI Integration with Vector Search
An embedded fraud detection model (e.g., trained on user behavior vectors) can run directly against the new order using pgvector.
- No need to duplicate vectors in a feature store
- Similarity queries run within the same transactional store
4. Zero-Copy Branching for Dev/Test
Want to simulate a flash sale or test a new promotion?
- Developers spin up a branch of the production database using zero-copy branching
- No full data copy, no downtime
- Tests run in isolation without impacting production
5. Built-in Governance and Observability
All data access, schema versions, and user permissions are managed through Unity Catalog.
- Centralized governance for both operational and analytical data
- Full audit trails and lineage for compliance
Conclusion: A New Standard for Modern Data Apps
Lakebase is more than just “Postgres in the cloud.” It’s a reimagined, unified engine that allows teams to transact, analyze, and serve AI—all in one place.
Whether you’re a software engineer trying to build scalable APIs, a data engineer fed up with ETL pipelines, or a product team racing to deliver personalized features—Lakebase collapses complexity and accelerates delivery.
With built-in support for real-time data, vector-based AI search, branching for safe testing, and instant analytics,
Opinions expressed by DZone contributors are their own.
Comments