Multimodal Deep Learning in Data Science
Multimodal Deep Learning is an advanced area of artificial intelligence that focuses on processing and integrating information from multiple data modalities such as text, images, audio, and video. Unlike traditional models that work with a single type of data, multimodal systems combine different sources of information to improve understanding, accuracy, and decision-making.
Understanding Multimodal Deep Learning
Multimodal deep learning is a field of artificial intelligence (AI) that focuses on building models capable of processing and understanding information from multiple types of data, such as text, images, audio, and video. Unlike traditional deep learning models that work with only one type of data, multimodal models combine information from different sources to produce more accurate and meaningful results.
For example, when humans communicate, we use multiple forms of information at the same time, speech (audio), facial expressions (visual), and gestures (movement). Multimodal deep learning aims to replicate this human ability by integrating different data sources to better understand complex information.
Why is Multimodal Deep Learning Important?
Multimodal deep learning is important as it reflects how humans understand, process, and interpret the world by combining information from multiple senses. By integrating different types of data, multimodal models provide more complete, accurate, and context-aware results, making them useful in many applications.
Below are some key reasons why multimodal deep learning is essential:
1. Enhanced Understanding of Complex Data
Many real-world situations involve multiple types of data that complement each other. For example:
- A video includes visual (frames), audio (speech or music), and text (subtitles).
- A medical diagnosis combines imaging data (X-rays, MRIs) with patient records.
- Multimodal models help AI understand data in a more complete and meaningful way, leading to deeper insights.
2. Improved Accuracy and Robustness
By using multiple data types, multimodal models can verify information from different sources. For example, in speech recognition, combining lip movements (visual) with audio improves accuracy, especially in noisy environments.
3. Human-Like Perception
Humans use multiple senses sight, hearing, and touch in order to understand the world. Multimodal systems mimic this ability, allowing AI to handle tasks that require understanding different inputs together, such as detecting emotions from both voice and facial expressions.
4. Real-World Applicability
Many real-world applications involve multiple data types:
- Healthcare: Combining medical images, lab results, and patient records for better diagnosis
- Autonomous Vehicles: Using cameras, LiDAR, and radar for safe navigation
- E-commerce: Using reviews, product images, and user behavior for recommendations
5. Context-Aware Decision Making
Multimodal models consider the broader context by combining different inputs.
For example, a voice assistant can use spoken commands (audio) along with visual information to perform tasks more accurately.
6. Handling Missing or Noisy Data
If one type of data is missing or unclear, other data sources can compensate.
Example: If a video’s audio is unclear, visual and text data can still provide useful information.
7. Innovation in Human-Computer Interaction (HCI)
Multimodal learning enables more natural interaction between humans and machines.
For instance, Ai systems can understand speech, gestures, and visual cues, improving experiences in virtual reality and assistive technologies.
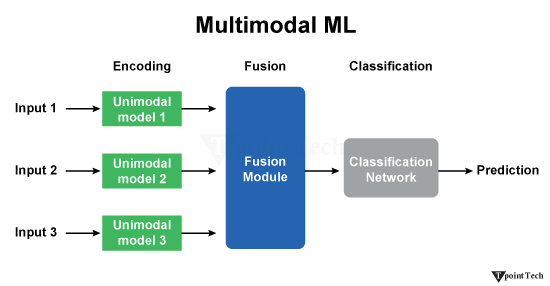
How Multimodal Deep Learning Works
Multimodal deep learning in data science is a method where models are trained to process and combine information from multiple data sources such as images, text, audio, and video. Unlike traditional (unimodal) models that handle only one type of data, multimodal models learn richer and more meaningful representations by combining different data types.
This approach is similar to how humans understand the world—by using multiple senses like vision, hearing, and language together.
For example:
- A video contains visual frames, audio, and sometimes subtitles
- A social media post may include both an image and text
Multimodal learning generally follows three main steps, which are as follows:
1. Modality-Specific Encoders
In the first step, each type of data (modality) is processed separately using specialized neural networks called encoders. Different data types require different models:
- Images: CNNs
- Text: Transformers (e.g., BERT)
- Audio : Spectrogram/Recurrent models
Each encoder extracts important features (embeddings):
These features are then mapped into a shared latent space:
This helps in combining and comparing different modalities.
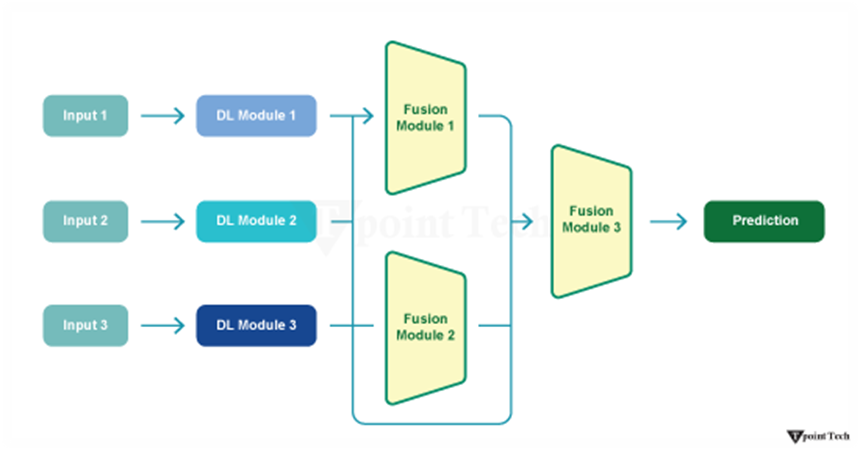
2. Fusion Techniques
After embedding each modality into a feature space, the individual representations are combined into a single fused representation for further processing and decision-making. Features from different modalities are combined:
- Early Fusion
- Late Fusion
- Hybrid Fusion
- Cross-Modal Attention
a. Early Fusion (Feature-Level Fusion)
In existing approaches, all modalities are combined very early in the architecture.
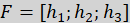
In simple fusion approaches, feature vectors of different object recognition modalities are concatenated to form a high-dimensional feature vector.
Alternatively, a weighted combination can be used:
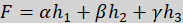
Where:
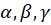 are the weights that define the relative importance of each modality.
are the weights that define the relative importance of each modality.
b. Late Fusion (Decision-Level Fusion)
In late fusion, each modality is processed independently, and its predictions are combined at the final stage.
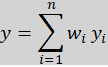
Where:
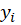 is the prediction from modality
is the prediction from modality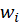 is the weight assigned to each modality?
is the weight assigned to each modality?
c. Hybrid Fusion (Intermediate Fusion)
Hybrid fusion is a technique that combines different data modalities at intermediate layers of a neural network. Unlike early fusion (which combines data at the beginning) and late fusion (which combines outputs at the end), hybrid fusion allows modalities to interact at multiple stages.
This approach helps the model capture meaningful relationships between different data types while also preserving the strengths of each modality. It provides a balance between early and late fusion methods and is widely used in modern multimodal deep learning architectures.
d. Cross-Modal Attention (Advanced Fusion)
Among the many different approaches to fusion, one of the most advanced and effective approaches to date is cross-modal attention. By allowing one modality to look at certain parts of another modality, cross-modal attention can greatly enhance the interaction and alignment between the two modalities.
Where:
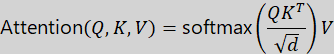
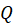 (Query) comes from one modality
(Query) comes from one modality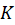 (Key) and
(Key) and 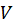 (Value) comes from another modality
(Value) comes from another modality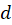 is a scaling factor to stabilize computation
is a scaling factor to stabilize computation
3. Classification and Prediction
After fusion, the combined feature vector is passed to a classifier to generate the final output.
Where:
- FFF = fused feature representation
- CCC = classification model (usually a neural network)
- yyy = predicted output
The classifier uses the combined information from all modalities to improve accuracy and robustness. Multimodal models generally perform better than unimodal models because they utilize information from multiple sources.
Multimodal Learning in NLP
Traditional natural language processing (NLP) methods that rely only on text are now being enhanced by multimodal approaches. These approaches combine different types of data such as text, images, and audio to improve understanding and performance.
- Image Captioning: It is used to generate meaningful text descriptions from images.
- Visual Question Answering (VQA): It is used for answering questions based on the content of an image.
- Multimodal Chatbots: It is helpful for providing more natural interaction with users by processing and responding to inputs such as text, images, and voice.
Applications of Multimodal Deep Learning
Multimodal deep learning allows computers to process and understand different types of data together, such as text, images, audio, and video. Like humans use multiple senses, this approach improves accuracy and enables smarter applications.
1) Healthcare
Multimodal AI helps doctors analyze different types of medical data together.
For example, it combines medical images (X-rays, MRIs) with patient records to improve diagnosis. Wearable devices also use it to monitor health data like heart rate and sleep patterns.
2) Self-Driving Cars
Self-driving cars use data from cameras, radar, and sensors to understand their surroundings.
By combining this information, they can make safe decisions, even in difficult conditions like fog or rain.
3) Voice Assistants and Smart Devices
Voice assistants like Alexa, Siri, and Google Assistant use multimodal learning to process voice and sometimes visual inputs.
They help users perform tasks such as playing music, checking weather, or controlling smart devices.
4) Emotion and Sentiment Analysis
Multimodal AI can detect emotions by analyzing facial expressions (images), voice tone (audio), and text.
It is useful in customer service and mental health monitoring.
5) Online Shopping (E-commerce)
E-commerce platforms use multimodal AI to improve user experience.
For example, users can search using images, and systems recommend products based on images, text, and browsing history.
6) Education
Multimodal systems make learning more interactive by combining videos, text, and quizzes.
They also support accessibility features like subtitles and sign language recognition.
Future Trends in Multimodal Deep Learning
Multimodal deep learning is rapidly evolving, leading to more intelligent, efficient, and human-like AI systems. Below are some key future trends:
1. Foundation Models for Multimodal AI
Large-scale foundation models are trained on multiple types of data (text, images, video, etc.) and can perform many tasks.
- Learn general features that can be reused across tasks
- Examples: image-to-text generation, video question answering
These models reduce the need for task-specific systems and speed up AI development.
2. Unified Multimodal Architectures
Future systems will use a single model to process multiple data types instead of separate models.
- One model can handle text, images, and audio together
- Reduces complexity and improves efficiency
This approach is inspired by how the human brain processes multiple senses together.
3. Few-Shot and Zero-Shot Learning
Modern multimodal models can learn from very little or no training data.
- Few-shot learning: Learning from a small number of examples
- Zero-shot learning: Performing tasks without prior training data
This improves flexibility and helps models handle new tasks more effectively.
4. Multimodal Reasoning
AI systems are becoming better at understanding and reasoning across multiple data types.
- Combining visual and textual information
- Performing logical reasoning using multiple inputs
This enables advanced tasks like answering questions based on videos and conversations.
5. Edge Deployment and Efficiency
There is growing interest in running multimodal models on devices like smartphones and IoT systems.
- Reducing model size and computation
- Using techniques like compression and quantization
This allows real-time applications such as augmented reality and smart assistants without relying on cloud computing.
Training Strategies in Multimodal Deep Learning
Training multimodal models requires special techniques to effectively combine information from different data types such as text, images, and audio. These strategies help improve accuracy, efficiency, and generalization.
1. Joint Training
In joint training, all modalities are trained together in a single model.
- Learns shared representations across different data types
- Captures interactions between modalities
- Requires well-aligned and synchronized data
2. Pretraining and Fine-Tuning
Models are first trained on large datasets for each modality and then fine-tuned for specific multimodal tasks.
- Improves performance using pre-learned features
- Example: combining a text model with an image model
3. Transfer Learning
Transfer learning uses knowledge gained from one task or modality and applies it to another.
- Reduces training time and computational cost
- Works well when labeled data is limited
4. Contrastive Learning
Contrastive learning helps models understand relationships between different modalities.
- Similar pairs (e.g., image and its caption) are brought closer
- Dissimilar pairs are pushed apart
Subscribe to Tpoint Tech
We request you to subscribe our newsletter for upcoming updates.
We deliver comprehensive tutorials, interview question-answers, MCQs, study materials on leading programming languages and web technologies like Data Science, MEAN/MERN full stack development, Python, Java, C++, C, HTML, React, Angular, PHP and much more to support your learning and career growth.
Contact info
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India
Follow us
