Download to read offline













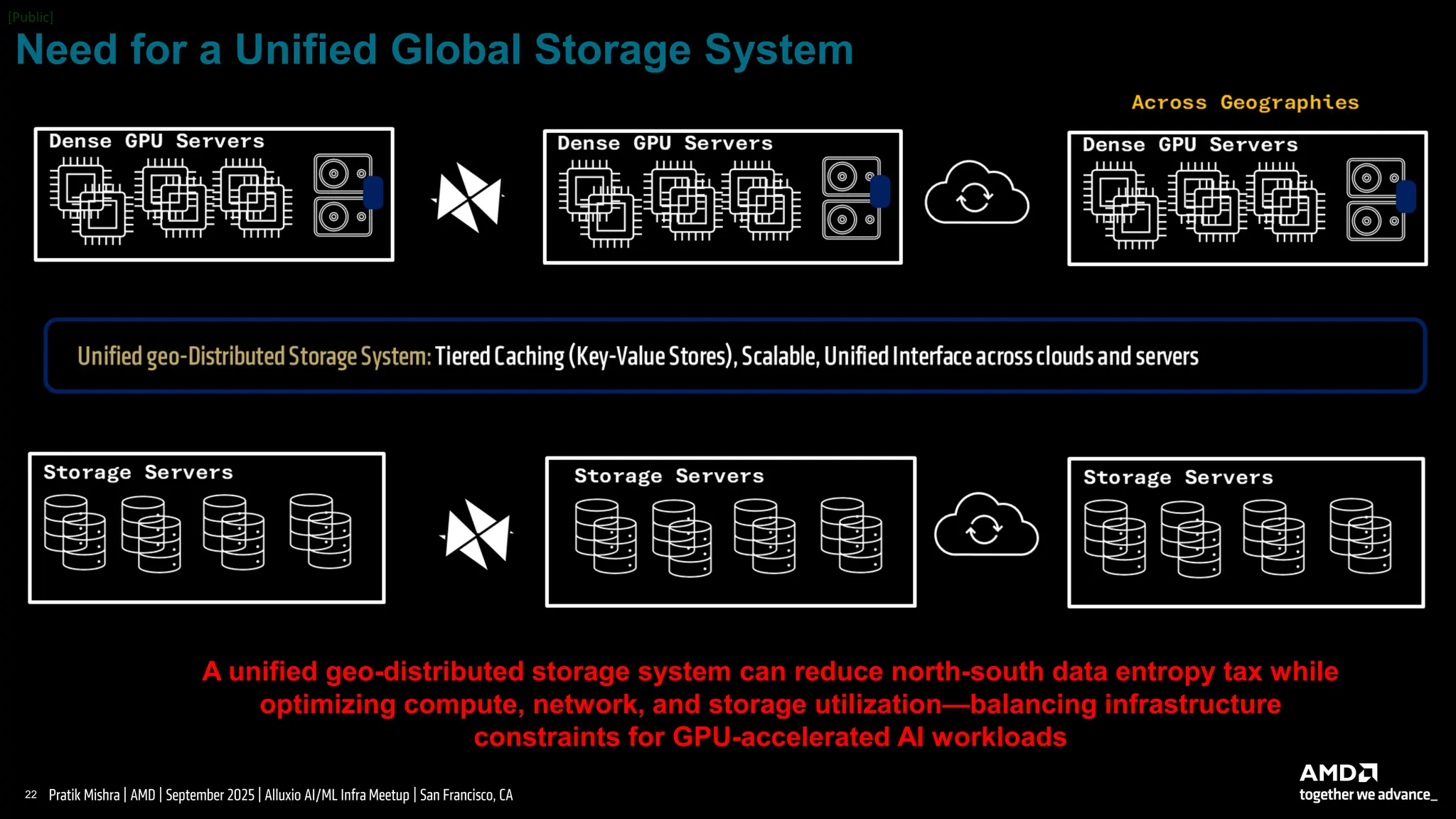





AI/ML Infra Meetup Sep. 30, 2025 Organized by Alluxio For more Alluxio Events: https://www.alluxio.io/events/ Speaker: - Pratik Mishra (Sr. Staff-Research @ AMD) Pratik Mishra delivered insights on architecting scalable, deployable, and resilient AI infrastructure at scale. His discussion on fault tolerance, checkpoint optimization, and the democratization of AI compute through AMD's open ecosystem resonated strongly with the challenges teams face in production ML deployments.