PDF files often contain critical embedded images (e.g., charts, diagrams, scanned documents). For developers, knowing how to extract images from PDF in Python allows them to repurpose graphical content for automated report generation or feed these visuals into machine learning models for analysis and OCR tasks.

This article explores how to leverage the Spire.PDF for Python library to extract images from PDF files via Python, covering the following aspects:
- Installation & Environment Setup
- How to Extract Images from PDFs using Python
- Handle Different Image Formats While Extraction
- Frequently Asked Questions
- Conclusion (Extract Text and More)
Installation & Environment Setup
Before you start using Spire.PDF for Python to extract images from PDF, make sure you have the following in place:
-
Python Environment: Ensure that you have Python installed on your system. It is recommended to use the latest stable version for the best compatibility and performance.
-
Spire.PDF for Python Library: You need to install the Python PDF SDK, and the easiest way is using pip, the Python package installer.
Open your command prompt or terminal and run the following command:
pip install Spire.PDF
How to Extract Images from PDFs using Python
Example 1: Extract Images from a PDF Page
Here’s a complete Python script to extract and save images from a specified page in PDF:
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("template1.pdf")
# Get the first page
page = pdf.Pages[0]
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Get the image information on the page
imageInfo = imageHelper.GetImagesInfo(page)
# Iterate through the image information
for i in range(0, len(imageInfo)):
# Save images to file
imageInfo[i].Image.Save("PageImage\\Image" + str(i) + ".png")
# Release resources
pdf.Dispose()
Key Steps Explained:
- Load the PDF: Use the LoadFromFile() method to load a PDF file.
- Access a Page: Access a specified PDF page by index.
- Extract Image information:
- Create a PdfImageHelper instance to facilitate image extraction.
- Use the GetImagesInfo() method to retrieve image information from the specified page, and return a list of PdfImageInfo objects.
- Save Images to Files:
- Loops through all detected images on the page
- Use the PdfImageInfo[].Image.Save() method to save the image to disk.
Output:
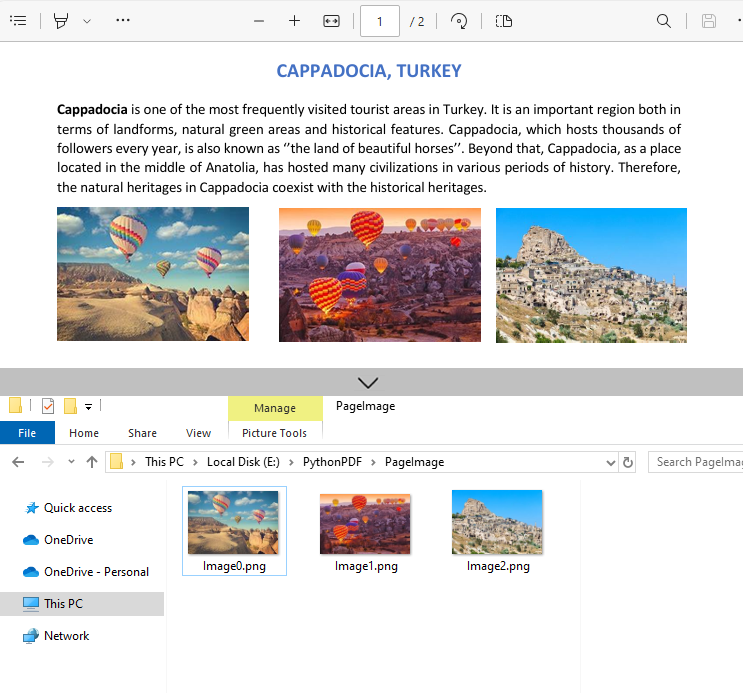
Example 2: Extract All Images from a PDF File
Building on the single-page extraction method, you can iterate through all pages of the PDF document to extract every embedded image.
Python code example:
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("template1.pdf")
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Iterate through the pages in the document
for i in range(0, pdf.Pages.Count):
# Get the current page
page = pdf.Pages[i]
# Get the image information on the page
imageInfo = imageHelper.GetImagesInfo(page)
# Iterate through the image information items
for j in range(0, len(imageInfo)):
# Save the current image to file
imageInfo[j].Image.Save(f"Images\\Image{i}_{j}.png")
# Release resources
pdf.Close()
Output:
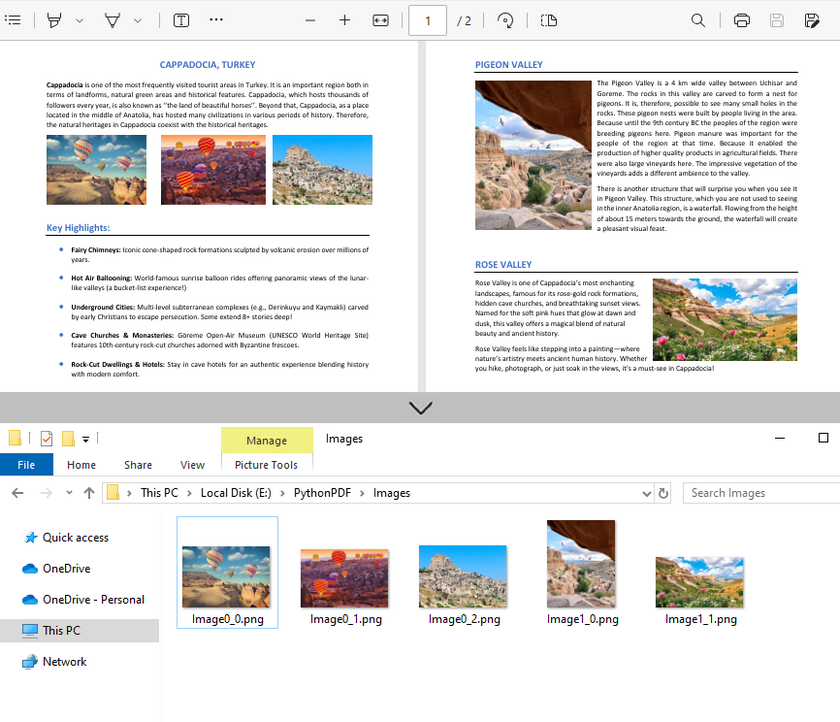
Handle Different Image Formats While Extraction
Spire.PDF for Python supports extracting images in various formats such as PNG, JPG/JPEG, BMP, etc. When saving the extracted images, you can choose the appropriate format based on your needs.
Common Image Formats:
| Format | Best Use Cases | PDF Extraction Notes |
|---|---|---|
| JPG/JPEG | Photos, scanned documents | Common in PDFs; quality loss on re-compress |
| PNG | Web graphics, diagrams, screenshots | Preserves transparency; larger file sizes |
| BMP | Windows applications, temp storage | Rare in modern PDFs; avoid for web use |
| TIFF | Archiving, print, OCR input | Ideal for document preservation; multi-page |
| EMF | Windows vector editing | Editable in Illustrator/Inkscape |
Frequently Asked Questions
Q1: Is Spire.PDF for Python a free library?
Spire.PDF for Python offers both free and commercial versions. The free version has limitations, such as a maximum of 10 pages per PDF. For commercial use or to remove these restrictions, you can request a trial license here.
Q2: Can I extract images from a specified page range only?
Yes. Instead of iterating through all pages, specify the page indices you want. For example, to extract images from the pages 2 to 5:
# Extract images from pages 2 to 5
for i in range(1, 4): # Pages are zero-indexed
page = pdf.Pages[i]
# Process images as before
Q3: Is it possible to extract text from images?
Yes. For scanned PDF files, after extracting the images, you can extract the text in the images in conjunction with the Spire.OCR for Python library.
A step-by-step guide: How to Extract Text from Image Using Python (OCR Code Examples)
Conclusion (Extract Text and More)
Spire.PDF simplifies image extraction from PDF in Python with minimal code. By following this guide, you can:
- Extract images from single pages or entire PDF documents.
- Save images from PDF in various formats (PNG, JPG, BMP or TIFF).
As a PDF document can contain different elements, the Python PDF library is also capable of:
