Table of contents:
The background
In CoinGecko we have multiple tables that we use to store crypto prices for various purposes. However, after over 8 years of data, one of the tables we store hourly data in grew over 1TB to a point it took over 30 seconds on average to query.
We started to see higher IOPS usage whenever there are more requests hitting price endpoints. Requests queues started to increase and our Apdex score started to go down. For a short term fix, we increased the IOPS up to 24K. However, the IOPS keeps on getting breached causing alerts everyday.
In order to ensure this situation doesn’t affect our SLO and eventually our SLA, we started to look into what we can do to improve the situation.
FYI, we are using PostgreSQL RDS as our main database.
The investigation
Adding indexes was initially considered the quickest solution, but this approach was unsuccessful. The query utilizes a JSONB column with keys based on supported currencies, presenting an additional challenge. Indexing different keys for various applications was deemed excessive, as an added index might only benefit a single application.
Ultimately, table partitioning was chosen as the solution most likely to yield the greatest returns, despite its complexity.
What is table partitioning?
Table partitioning involves dividing a large table into smaller, more manageable pieces called partitions. These partitions share the same logical structure as the original table but are physically stored as separate tables.
This allows queries to operate on only the relevant partitions, improving performance by reducing the amount of data scanned.
There are three methods of partitions which are:
- Range: Partitions data based on a range of values (e.g., dates, numerical ranges).
- List: Partitions data based on specific list values (e.g., countries, categories).
- Hash: Partitions data by applying a hash function to a column's value, distributing data evenly across partitions.
The question is, which partitioning method should we use? As usual, the answer is: it depends. We need to analyze our query patterns to determine which method will provide the greatest benefit. The key is to select the method that minimizes the amount of data our queries need to read every time it runs.
In our case, range partitioning is the optimal choice. This is due to the fact that almost all of our queries on this table incorporate a timestamp range in the WHERE clause. Moreover, we know that we generally only require data for a few months at a time, with a maximum of four. As a result, partitioning the table by month will guarantee that our queries only access up to four partitions (most of the time).
IF for some reason, we are not limiting the read based on the timestamp, we may need to use the Hash method as that will limit the read based on a foreign key. Again, it depends on the use case.
What would the code look like?
CREATE TABLE orders (
id SERIAL,
customer_id INTEGER,
order_date DATE,
amount DECIMAL(10,2)
) PARTITION BY RANGE (amount);
-- Create partitions for different amount ranges
CREATE TABLE orders_small
PARTITION OF orders
FOR VALUES FROM (0) TO (100);
CREATE TABLE orders_medium
PARTITION OF orders
FOR VALUES FROM (100) TO (500);
CREATE TABLE orders_large
PARTITION OF orders
FOR VALUES FROM (500) TO (1000);
CREATE TABLE orders_extra_large
PARTITION OF orders
FOR VALUES FROM (1000) TO (MAXVALUE);
-- Insert sample data
INSERT INTO orders (customer_id, order_date, amount) VALUES
(1, '2024-01-15', 50.00), -- Goes to orders_small
(2, '2024-01-15', 150.00), -- Goes to orders_medium
(3, '2024-01-15', 600.00), -- Goes to orders_large
(4, '2024-01-15', 1200.00), -- Goes to orders_extra_large
(5, '2024-01-15', 75.00), -- Goes to orders_small
(6, '2024-01-15', 450.00); -- Goes to orders_medium
In my case, I just name the partition based on this format: table_YYYYMM.
What did I learn during the investigation?
If someone had to do this again, these are the info that I will pass on:
- We can’t change the table from an unpartitioned table to a partitioned table. We need to create a new table and copy the data into it before making the switch.
- The partitioned table needs to have the partition key as part of the primary key. If we have ID as the original primary key, then, we need to use composite keys on the new table.
- In order to use partitioned tables in Ruby on Rails, we need to change the schema format from
schema.rbtoschema.sql. - We need to figure out how to have both tables running at the same time if we can’t afford downtime.
- Since we will be creating a new table, we have to be careful about the cache. Technically, the new table doesn’t have cache at all and the performance will be very bad. We have to figure out how to “warm” up the new table. I am referring to the cache in PostgreSQL itself.
- To warm up the table, please learn about pg_prewarm.
- Copying data as big as 1.2TB would require bigger resources such as IOPS. We need to take that into account.
With all the info that we had, we created a Release Plan document outlining when and what is going to happen. We used that document as our main reference point for everyone to see. The document contains these info:
- Date: When it is going to happen.
- Prerequisites: Before executing the todos, we may need to do other tasks first. They will be listed in this section ensuring we do not start the todos without completing them.
- Risks: For every risk, we will list down what could happen and what are the mitigation plans.
- Todos: This section will list down what needs to be done and once it is done, we will tick them off from the list.
The execution
Dry Run
Our customers are very particular about the uptime of our services, hence, we proactively conduct dry runs to safeguard our SLO/SLA commitments. Before we start our dry run, we will list down what we want to do and what kind of statistics that we want to collect.
For this project, we spinned up another database identical to our production. Then, we ran all the commands or scripts that we will run on the production instance later. In our case, we were looking for these data:
- Before and after query performance.
- How long will it actually take to copy the data?
- How long does it take to warm up the table partitions?
- What does the CPU and IOPS look like for every action that we did?
Avoid operating in the dark.. Be prepared so that we won’t miss our objectives. Remember, using a database similar to our production is going to cost a lot of money.
What we found out during the dry run:
- The original table was too slow at first. But, this is expected as without any cache, we won’t be able to work on it.
- It took us 10 hours to just warm up the original table before we could start trying out our commands.
- It took us 3 days+ to finish copying the data.
- Total IOPS can spike up to 6,000 during this operation, even when running in isolation without any other database workload. To put this in perspective, 6,000 IOPS for the read is virtually identical to what our production database handles under normal operating conditions.
- We can get 6-8x performance based on the same query that we had when we switched to partitioned tables.
- Prewarming the partitioned table only took 3 hours compared to the original table which was 10 hours.
Once we have the right statistics, we made the necessary arrangements such as:
- Announcing the day and time where we will do this on the production database.
- Increase the storage capacity to ensure our database can fit the new table and still have extra spaces left until we drop the original table. We also need to consider the amount of storage needed for everyday tasks.
- Increase the IOPS so that the Primary and the Replicas can handle the load due to the data copy process.
Go-Live Day
The work will start at the beginning of the week to minimize weekend work and ensure our engineers have a peaceful weekend. We also have a backup engineer and SRE support.
It’s quite normal that things didn’t go as planned, but the first challenge was something that I didn’t expect at all.
Challenge #1: Our original table was so bad that I couldn’t even complete copying one day's worth of data.
Based on what we did during the dry run, we should be able to copy one day of data within 2-3 minutes. However, when it comes to production, I didn’t expect it was going to be much worse. Technically, the production data should have sufficient cache as it is actively being used. I didn’t spend too much time looking into it, but I know I can’t warm up the table as we won’t have enough IOPS for it.
We have 8 years of data that we need to copy. So, imagine waiting 15 minutes for 1 day of data. Actually, I don’t know how long it would take as I just kill the query after 15 minutes.
What was the solution? Well, we know for a fact from our dry run, if we warm up the table, it will only take 2-3 minutes for one day of data. But, we cannot warm up our production’s table. So, what can we do?
I remember a Postgres feature called Foreign data wrappers. Basically, we will read from another host and write to the partitioned table in the production’s host. This way, we don’t have to warm up the table in the production and we also won’t use too much IOPS as well. This seems like a win to us.
Based on that idea, we improvised our plan for a little bit:
- Provision another production grade database.
- Prewarm the table.
- Setup Foreign data wrapper.
- Update our copy script to read from the new host and write to the current production’s database.
This whole process set us back by two to three days. But, it’s something that we cannot avoid.
Challenge #2: Warming up all databases, including replicas, was necessary
We didn't realize we needed to warm up our replicas until the go-live day began. We had only been focusing on the primary database. This oversight added extra work to the process but at least we are not so worried about the partitions not warmed up enough in the replicas.
The final query
Once we have gone through all of the tasks, we just flip the switch by renaming the table:
BEGIN;
-- Remove existing trigger
DROP TRIGGER IF EXISTS ...;
-- THE IMPORTANT BITS
ALTER TABLE prices RENAME TO prices_old;
ALTER TABLE prices_partitioned RENAME TO prices;
-- Create the trigger function
CREATE OR REPLACE FUNCTION sync_prices_changes_v2()
RETURNS TRIGGER AS $$
BEGIN
-- ...
END;
$$ LANGUAGE plpgsql;
-- Attach the trigger on the new table so that prices_old will get the changes
CREATE TRIGGER sync_to_partitioned_table
AFTER INSERT OR UPDATE OR DELETE ON prices
FOR EACH ROW
EXECUTE FUNCTION sync_prices_changes_v2();
COMMIT;
As you can see, we are using triggers to copy the data from and to the new and the old table. We still need the old table. Remember, things could go wrong and we need our Plan B, C and so on.
What We Did Right
- Table warm-ups: Based on past experience from the database upgrade, we made the right call to warm up the partitions. This ensured that query time didn't increase when we switched from the unpartitioned table to the partitioned table.
- Scripted the tasks: We prepared scripts for every task and developed a small Go app to manage data copying. The app included essential features like timestamps, the ability to specify the year for data copying, and the time taken to copy data. We also created an app for warming up the table, allowing us to carefully manage CPU and IOPS usage.
- Used CloudWatch Dashboard: We decided to fully utilize CloudWatch Dashboard for this project, and it proved invaluable for monitoring IOPS, CPU, Replica Lag, and other metrics across multiple replicas. Learning to set up the vertical line feature was particularly helpful for visualizing before-and-after comparisons.
- Team Backup: Having backup from another person or team was beneficial. They helped identify things we might have missed and provided a sounding board for ideas during planning and execution.
The result
Now let’s go to the fun part. However, there was also a regression after we switched to the partitioned table. Details are in the “What we would do differently” section.
When we are talking about the result, we should return back to why we are doing this in the first place. On the micro level, we want to reduce the IOPS for certain queries. On the macro level, we want our endpoints to be faster and more resilient towards requests spikes. Severe high IOPS can cause replica lags as well.
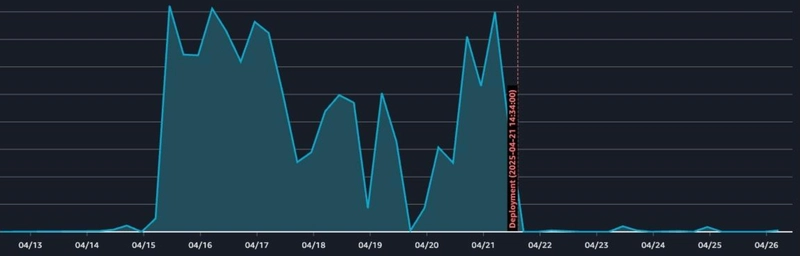
IOPS
The IOPS was reduced by 20% right after this exercise. Since this table was being used extensively across all of our applications, we can reduce the maximum IOPS thus allowing us to save our costs further. To be clear, we are running multiple replicas so the cost savings are multiplied by the number of replicas that we have.
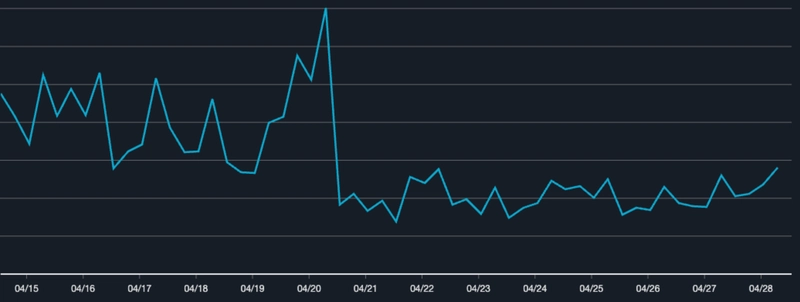
Response Time
This was quite significant as we managed to reduce the p99 from 4.13s to 578ms. That is a about 86% reduction in terms of the response time. You can see how flat the chart is right after we made the switch.
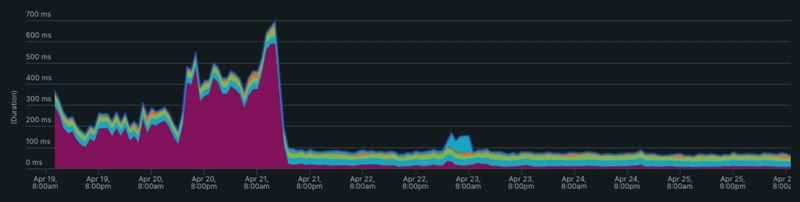
Replica Lag
Right before we made the table switch, we had increased usage of the affected endpoints causing higher IOPS which in result caused us replica lags. But, it went away the moment we flipped to the partitioned table.
What we would do differently
Block the deployments
The biggest mistake in our planning was not blocking deployments on the day of the switch. While the switch itself wouldn't disrupt others' work, we overlooked the fact that two deployments were related to the table we were optimizing. This caused confusion about the impact of the table partitioning.
The higher CPU and IOPS utilization observed after the switch put the exercise at risk of rollback. We eventually identified that an earlier deployment caused the problem. However, pinpointing the cause required rolling back the changes and extensive discussion. This situation could have been avoided by blocking deployments for a day to clearly assess the impact of our changes.
Too focused on the replicas
Our focus on resolving the replica issue led us to overlook the impact on the primary database. We failed to identify which queries would be affected, and one query, in particular, performed worse after the switch. This query triggered scans across all of the table partitions, increasing IOPS and CPU usage. By modifying the query, we managed to resolve it.
This experience highlighted that without the correct query, table partitioning can be detrimental. In this instance, the query lacked a lower limit for the date range, resulting in all partitions being scanned unnecessarily. Interestingly, the same query performed well on the unpartitioned table.
Extra partitions
This was another instance where we noticed a regression on one endpoint that helped us realize the mistake.
To reduce the future workload of creating partitions, we initially created all the partitions for 2025. We discovered that one query was structured like 'created_at > ?' without an upper limit. It caused the query to scan future partitions that were empty. By removing these partitions, we fixed the issue.
Going forward, we need to determine a better strategy for when to create future partitions.
Incremental release
We shouldn’t have waited for the entire table to be migrated before starting to use it. Since most users only access data from the last four partitions (or months), we could have implemented a feature toggle to direct queries for data after a specific date to the already migrated partitioned tables.
This approach would have allowed us to start using the partitioned tables sooner and reduced the risks and potential negative impact of any issues that might arise. As it stands, rolling back our changes would be costly in terms of IOPS, as we would need to prewarm the old table again to avoid production downtime due to cold cache.
Summary
This is just the beginning. With this experience under our belt, we can start exploring the possibility of implementing table partitions on other tables as well. Of course, table partitioning isn't a one-size-fits-all solution. We need to diagnose the issue before proceeding. Sometimes, something as simple as adding an index can resolve the problem.
In conclusion, while partitioning the 1TB+ "prices" table presented some challenges, especially during the go-live phase, the overall outcome was substantial performance improvements. This initiative aligns with the API Team's ongoing goal: providing the best possible experience to better serve our customers. Our API is now more stable and resilient against sudden spikes in requests during peak hours.

Top comments (5)
Would the TimescaleDB extension help automate most of these steps and reduce the need for manual selection of partitions, handling of future dates partitions etc.?
It would, but timescale db is not available on RDS.
Yeah. I had the same thoughts! But at the same time, good to learn about someone going through all the steps and reporting back with blockers and workarounds
Very nice sharing...thankyou !!
Pretty cool seeing all the behind the scenes work that actually makes things faster, feels familiar and I’m honestly glad you shared the gritty parts
Some comments may only be visible to logged-in visitors. Sign in to view all comments.