I'm learning about "Functional Core, Imperative Shell" as espoused by Gary Bernhardt in his talk about "Boundaries". In reality, it seems like these ideas have been known for a long time, and put into practice with languages like Elm or Haskell. Gary has just articulated them very well and to an audience that is unfamiliar with the ideas.
What I want to know is how to handle lots of I/O from within the core. A modern application, especially on the web, can't help but have a ton of it. Getting users from the database, checking if access tokens are expired through introspection, renewing them, writing to the database, calling an external API to parse natural language, writing logs virtually everywhere, random values for encryption virtually everywhere. It doesn't seem linear to me at all about the so called "imperative shell".
So how can one reconcile these two principles?
One idea might be to write some kind of interpreter, that parses the response of a function and returns the next function for the interpreter to run. Then you have exactly zero decisions to make in the shell and just one big switch statement of all your core functions.
But... is this ultimate conclusion really better? Does you think it improves the architecture? Are there better ways?
To reiterate. The simple way:
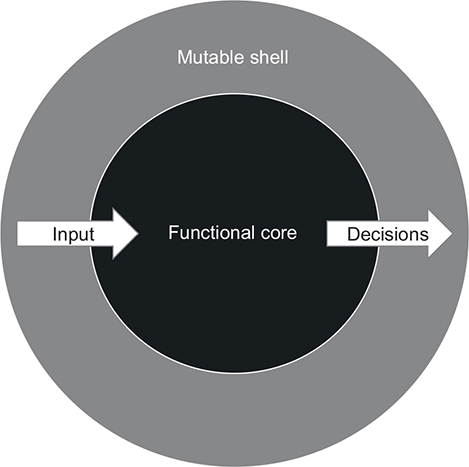
But now image that core, is constantly needing the shell to do work and effectively make a lot of decisions.