Snowflake の COMPLETE関数のマルチモーダル機能の価値
はじめに
Snowflake の生成 AI 機能群である Cortex AI において2025/4/14に Cortex COMPLETE Multimodal がパブリックプレビューとなりました。
既に LLM の世界では画像を読み込めるようになって久しいですが、Cortex AI の汎用 LLM 関数である COMPLETE 関数 においても画像分析ができるようになりました。これは単にマルチモーダル LLM が楽にセキュアに使えるようになったというだけではなく、これまでのデータワークロードに新たな価値を追加できるということです。今回はこの COMPLETE 関数のマルチモーダル機能についてご紹介します。
Cortex COMPLETE Multimodal とは?
Cortex COMPLETE Multimodal は、COMPLETE 関数を使用して画像を解析できる機能です。この機能により、以下のような処理が SQL や Python のみで実現できます:
- 画像の比較
- 画像のキャプション生成
- 画像の分類
- 画像からのエンティティ抽出
- グラフやチャートのデータに基づく質問への回答
画像処理が必要な場合、これまでは外部の API やサービスを利用するか、Python に OpenCV などのライブラリを追加して複雑な処理を実装する必要がありました。しかし、この機能を使えば SQL クエリなどデータ活用の流れの中で画像処理ができるため、データパイプラインをよりシンプルにし、気軽にデータワークロードに画像処理機能をアタッチすることが可能となります。
利用できるモデル
現在 COMPLETE 関数のマルチモーダル機能では以下のモデルが利用可能です:
Anthropic Claude シリーズ
Claude 4 Opus:最も高性能な Anthropic のフラッグシップモデル
- 設定するモデル名:claude-4-opus
- コンテキストウィンドウ:200,000トークン
- 対応ファイルタイプ:.jpg .jpeg .png .webp .gif
- 対応ファイルサイズ: 3.75MB
- プロンプトあたり最大画像枚数: 20枚
Claude 4 Sonnet:高性能とコストのバランスが優れたモデル
- 設定するモデル名:claude-4-sonnet
- コンテキストウィンドウ:200,000トークン
- 対応ファイルタイプ:.jpg .jpeg .png .webp .gif
- 対応ファイルサイズ: 3.75MB
- プロンプトあたり最大画像枚数: 20枚
Claude 3.7 Sonnet:改良されたSonnetバージョン
- 設定するモデル名:claude-3-7-sonnet
- コンテキストウィンドウ:200,000トークン
- 対応ファイルタイプ:.jpg .jpeg .png .webp .gif
- 対応ファイルサイズ: 3.75MB
- プロンプトあたり最大画像枚数: 20枚
Claude 3.5 Sonnet:高度な視覚処理能力と言語理解能力を持つ Anthropic のマルチモーダルモデルで既に多くの企業で採択されている実績のあるモデル
- 設定するモデル名:claude-3-5-sonnet
- コンテキストウィンドウ:200,000トークン
- 対応ファイルタイプ:.jpg .jpeg .png .webp .gif
- 対応ファイルサイズ: 3.75MB
- プロンプトあたり最大画像枚数: 20枚
Mistral AI シリーズ
Pixtral Large:Mistral AI による視覚的推論タスクに優れたモデルで日本語を含む多言語サポートをしているモデル
- 設定するモデル名:pixtral-large
- コンテキストウィンドウ:128,000トークン
- 対応ファイルタイプ:.jpg .jpeg .png .webp .gif .bmp
- 対応ファイルサイズ: 10MB
- プロンプトあたり最大画像枚数: 1枚
Meta Llama シリーズ
Llama 4 Maverick:Meta の最新マルチモーダルモデル
- 設定するモデル名:llama4-maverick
- コンテキストウィンドウ:128,000トークン
- 対応ファイルタイプ:.jpg .jpeg .png .webp .gif .bmp
- 対応ファイルサイズ: 10MB
- プロンプトあたり最大画像枚数: 10枚
Llama 4 Scout:効率性に優れたLlamaシリーズのモデル
- 設定するモデル名:llama4-scout
- コンテキストウィンドウ:128,000トークン
- 対応ファイルタイプ:.jpg .jpeg .png .webp .gif
- 対応ファイルサイズ: 10MB
- プロンプトあたり最大画像枚数: 10枚
モデル性能ベンチマーク
各モデルの性能は以下のベンチマークで評価されています:
| Model | MMMU | Mathvista | ChartQA | DocVQA | VQAv2 |
|---|---|---|---|---|---|
| llama4-maverick | 73.4 | 73.7 | 90.0 | 94.4 | - |
| llama4-scout | 69.4 | 70.7 | 88.8 | 94.4 | - |
| claude-3-5-sonnet | 68.0 | 64.4 | 87.6 | 90.3 | 70.7 |
| pixtral-large | 64.0 | 69.4 | 88.1 | 85.7 | 67.0 |
リージョン対応状況
Cortex COMPLETE Multimodal はクロスリージョン推論機能を有効化することで、クラウドやリージョンの制限無くご利用いただくことが可能です。
詳細な対応状況は公式ドキュメントをご確認ください。
準備:画像用のステージを作成
まずは画像を格納するためのステージを作成します。サーバーサイド暗号化とディレクトリテーブルを有効にする必要があります。(ここでは SQL クエリで記載していますが、Snowsight から GUI で操作していただいても問題ありません)
-- 内部ステージの作成
CREATE OR REPLACE STAGE image_stage
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
次に、ステージに画像をアップロードします。対応している画像形式は .jpg, .jpeg, .png, .webp, .gif, .bmp です。(.bmp は Pixtral Large と Llama 4 Maverick のみ対応しています)
-- 画像のアップロード
PUT file:///path/to/your/image.jpg @image_stage
AUTO_COMPRESS = FALSE;
実践例:画像分析
例1: 画像のキャプション生成
画像の内容を説明するキャプションを生成する例です。非常にシンプルなクエリ構造で、これまでの COMPLETE 関数に引数を1つ追加してステージ上の画像ファイルを渡すだけです。
-- Cortex COMPLETE Multimodal を用いた画像キャプション生成
SELECT SNOWFLAKE.CORTEX.COMPLETE('<モデル名>,
'この画像について簡潔に日本語で説明してください。',
TO_FILE('@<ステージ名>', '<画像ファイル名>'));

上記画像 (私が会社で歌っている画像) に対する出力結果は以下の通りです。どちらも日本語を理解し日本語で出力してくれますので嬉しいですね!
-- claude-3-5-sonnet の出力結果
グレーのタートルネックセーターを着た人物がマイクを持って歌っている様子です。背景にはオレンジと白のストライプの壁が見えます。カラオケやライブパフォーマンスの一場面のように見えます。
-- pixtral-large の出力結果
この画像は、緑色のニットのセーターを着た人物が、黒いカメラを目に当てている様子を描いています。背景には、オレンジと白の縞模様があり、その中に緑色の植物が見えます。人物はカメラを使って何かを撮影しているようで、その表情は集中しているように見えます。
例2: 複数画像の比較
2つの画像を比較し、違いを説明する例です。クエリ構造が少し例1とは異なっていますのでご注意ください。画像は最大100枚まで渡すことができ、現状は claude シリーズと llama シリーズが複数画像処理に対応しております(pixtral-large は1枚のみ対応)。
また PROMPT 関数内には各画像ファイルに対応した分のプレースホルダが必要となります。下のクエリにおいては {0} と {1} の部分で、それぞれ「1枚目の画像ファイル」と「2枚目の画像ファイル」を指しています。
SELECT SNOWFLAKE.CORTEX.COMPLETE('claude-3-5-sonnet',
PROMPT('{0}と{1}の2つの画像について共通点を抽出してください。',
TO_FILE('@<ステージ名>', '<画像ファイル名>'),
TO_FILE('@<ステージ名>', '<画像ファイル名>')));

上記2枚の画像 (私が会社で歌っている画像と私が展示会でブースに立っている画像) に対する出力結果は以下の通りです。想定以上にちゃんとした分析ができており、どちらも同一人物だと正しく判断していますね。
-- claude-3-5-sonnet の出力結果
これらの2つの画像の主な共通点は以下の通りです:
1. 同じ人物が写っており、特徴的な髪型(レイヤーカットのような黒髪で前髪がある)をしています
2. 室内での撮影で、展示会やイベント会場のような業務用スペースで撮影されています
3. 背景に展示用の壁面やディスプレイが見えます(1枚目はオレンジと白のストライプ、2枚目はSnowflakeのブース)
4. ビジネスカジュアルな服装で写っています(1枚目はグレーのタートルネックセーター、2枚目は業務用の制服やビジネスウェア)
5. どちらも技術系やビジネス系のイベントや展示会での様子を捉えた写真のように見えます
例3: 画像からの情報抽出
たった今10秒で描いた手書きの図から情報抽出をしてみます。
SELECT SNOWFLAKE.CORTEX.COMPLETE('<モデル名>',
'この画像は手書きのアーキテクチャ図です。どういう構成なのか詳細に説明してください。',
TO_FILE('@<ステージ名>', '<画像ファイル名>'));
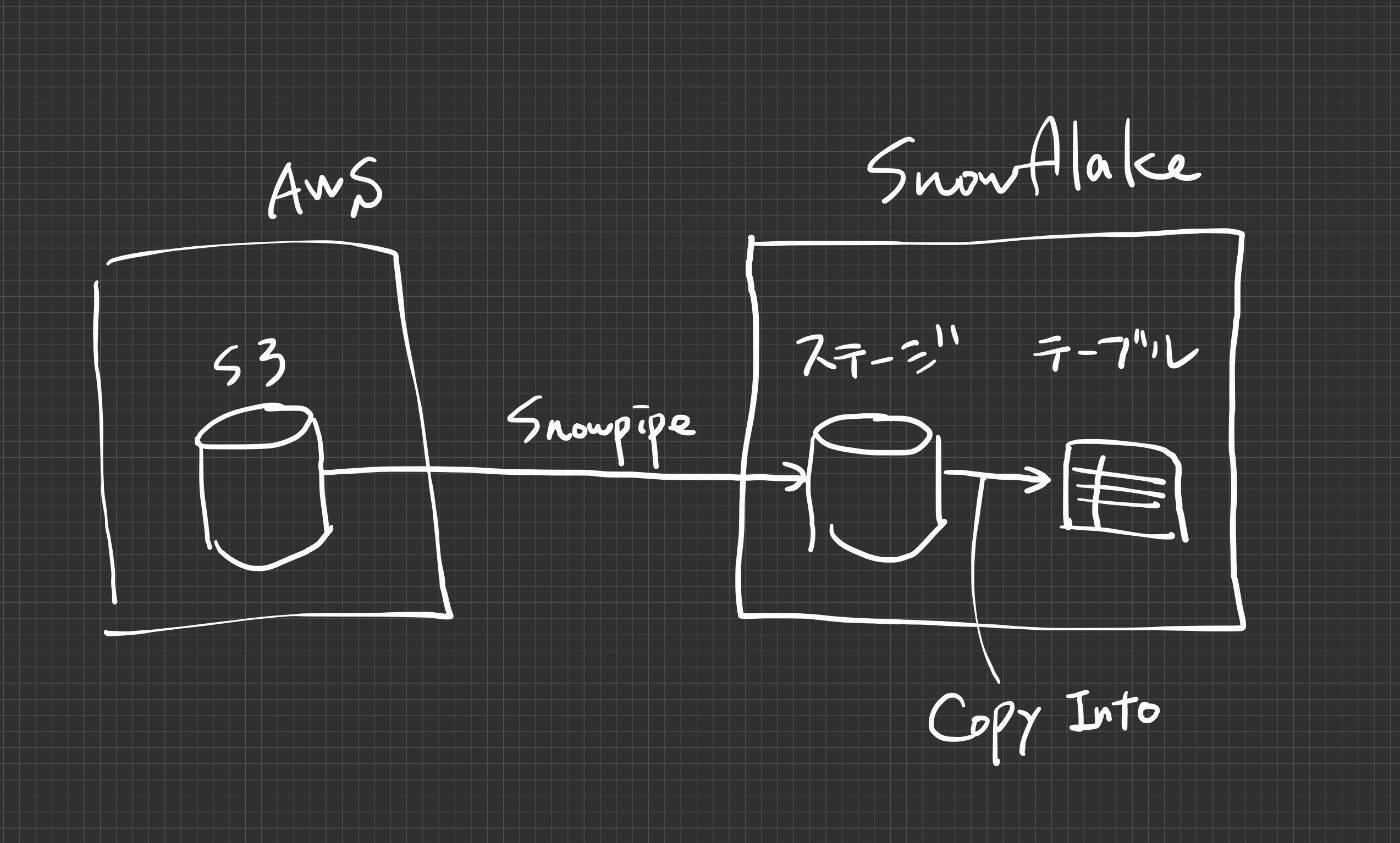
上記画像 (すごく適当な手書きのアーキテクチャ図) に対する出力結果は以下の通りです。非常に高い精度で画像を理解し解説できています。
-- claude-3-5-sonnet の出力結果
この図は、AWSとSnowflakeを連携させるアーキテクチャを示しています。主な構成要素は以下の通りです:
1. AWS側:
- S3バケットが配置されており、データソースとして機能しています
2. 連携部分:
- Snowpipeを使用してデータ転送を行っています
- これはAWS S3からSnowflakeへの自動データロード機能です
3. Snowflake側:
- ステージングテーブルがあり、S3からのデータを受け取ります
- Copy Infoという記述があり、これはおそらくCOPY INTOコマンドを使用してデータをロードする処理を示していると思われます
このアーキテクチャは、AWS S3に保存されているデータをSnowpipeを使って準リアルタイムでSnowflakeにロードする、一般的なデータパイプラインの構成を表しています。Snowpipeを使用することで、S3にデータが配置されると自動的にSnowflakeへのロードが開始される仕組みになっています。
-- pixtral-large の出力結果
この画像は、AWSとSnowflakeの間でデータを移動するためのアーキテクチャを示しています。以下は詳細な説明です:
1. **AWS**:
- AWSのセクションには、「S3」とラベルが付けられたバケツが含まれています。これは、Amazon Simple Storage Service(S3)バケツを表しています。
2. **Snowflake**:
- Snowflakeのセクションには、「ステージ」と「テーブル」とラベルが付けられたバケツが含まれています。
- 「ステージ」は、Snowflake内の一時的なストレージエリアを表しています。
- 「テーブル」は、Snowflakeデータベース内のテーブルを表しています。
3. **Snowpipe**:
- AWS S3バケツとSnowflakeステージの間に「Snowpipe」とラベルが付けられた矢印があります。
- Snowpipeは、S3バケツからSnowflakeステージにデータを自動的にロードするためのSnowflakeのサービスです。
4. **データフロー**:
- データは、AWS S3バケツからSnowflakeステージにSnowpipeを介して移動します。
- Snowflakeステージからデータは「コピーイント」操作を介してSnowflakeテーブルにロードされます。
要約すると、このアーキテクチャは、AWS S3バケツからSnowflakeステージにデータを移動し、その後Snowflakeテーブルにロードするためのプロセスを示しています。このプロセスは、Snowpipeを使用して自動化され、Snowflakeの「コピーイント」コマンドを使用してデータをテーブルにロードします。
コスト考慮事項
料金は処理されるトークン数に応じて課金されます。画像あたりのトークン数は、視覚モデルのアーキテクチャによって異なります:
- Anthropic (Claude) モデル: トークン数 = (画像幅ピクセル × 画像高さピクセル) / 750
- Mistral (Pixtral) モデル: 画像を16×16ピクセルのバッチに分割し、各バッチを1トークンに変換。総トークン数 = (画像幅ピクセル / 16) × (画像高さピクセル / 16)
- Meta (Llama) モデル: 画像を正方形のタイルで分割。画像のアスペクト比とサイズに応じて最大16タイル、各タイル約153トークン
効率的なコスト管理のために、タスクの複雑さと処理する画像のサイズに応じて適切なモデルを選択することが重要です。
またテクニックとして、画像を縮小してから渡すことでコストの最適化や、処理速度の向上を図ることも可能です。
ビジネスアイディア
マルチモーダル機能は例えば以下のようなビジネスシーンで活用できます:
- EC サイトの商品画像管理: 商品画像から自動的に説明文やタグを生成
- 不動産写真の分析: 不動産写真から間取りや特徴を自動抽出
- 文書画像からのデータ抽出: 請求書や契約書などの画像からデータを構造化して取得
- 医療画像の整理と検索: 医療画像に自動的にメタデータを付与
- SNS 投稿の画像分析: マーケティング目的でSNS画像の内容を分析
更に Streamlit in Snowflake など既存の Snowflake の機能と組み合わせることで、データアプリケーションの可能性が更に広がります。是非皆様のアイディアを Cortex COMPLETE Multimodal を使って実現してみてください。
最後に
COMPLETE 関数のマルチモーダル機能はかなり強力で、標準で準備されている関数だけでここまで高度な画像処理ができるのは間違い無くポジティブです。特に既存の Snowflake ワークフローに統合でき、データから更なる価値を引き出すことができるところが大事な点です。本記事では基本的な機能のみご紹介させていただきましたが、これから Cortex COMPLETE Multimodal を用いた応用例についても近々お届けしますので楽しみにしていてください。
宣伝
SNOWFLAKE DISCOVER で登壇しました!
2025/4/24-25に開催されました Snowflake のエンジニア向け大規模ウェビナー『SNOWFLAKE DISCOVER』において『ゼロから始めるSnowflake:モダンなデータ&AIプラットフォームの構築』という一番最初のセッションで登壇しました。Snowflake の概要から最新状況まで可能な限り分かりやすく説明しておりますので是非キャッチアップにご活用いただければ嬉しいです!
以下リンクでご登録いただけるとオンデマンドですぐにご視聴いただくことが可能です。

生成AI Conf 様の Webinar で登壇しました!
『生成AI時代を支えるプラットフォーム』というテーマの Webinar で NVIDIA 様、古巣の AWS 様と共に Snowflake 社員としてデータ*AI をテーマに LTをしました!以下が動画アーカイブとなりますので是非ご視聴いただければ幸いです!
X で Snowflake の What's new の配信してます
X で Snowflake の What's new の更新情報を配信しておりますので、是非お気軽にフォローしていただければ嬉しいです。
日本語版
Snowflake の What's New Bot (日本語版)
English Version
Snowflake What's New Bot (English Version)
変更履歴
(20250415) 新規投稿
(20250416) 対応クラウドとリージョンに関する情報を追記
(20250421) 対応ファイルサイズの修正、PROMPT 関数の補足を追記
(20250508) 宣伝文修正
(20250601) 利用可能モデルのアップデート(Claude 4シリーズ、Llama 4シリーズ追加)、モデル性能ベンチマーク表の追加、コスト考慮事項の詳細化
Discussion