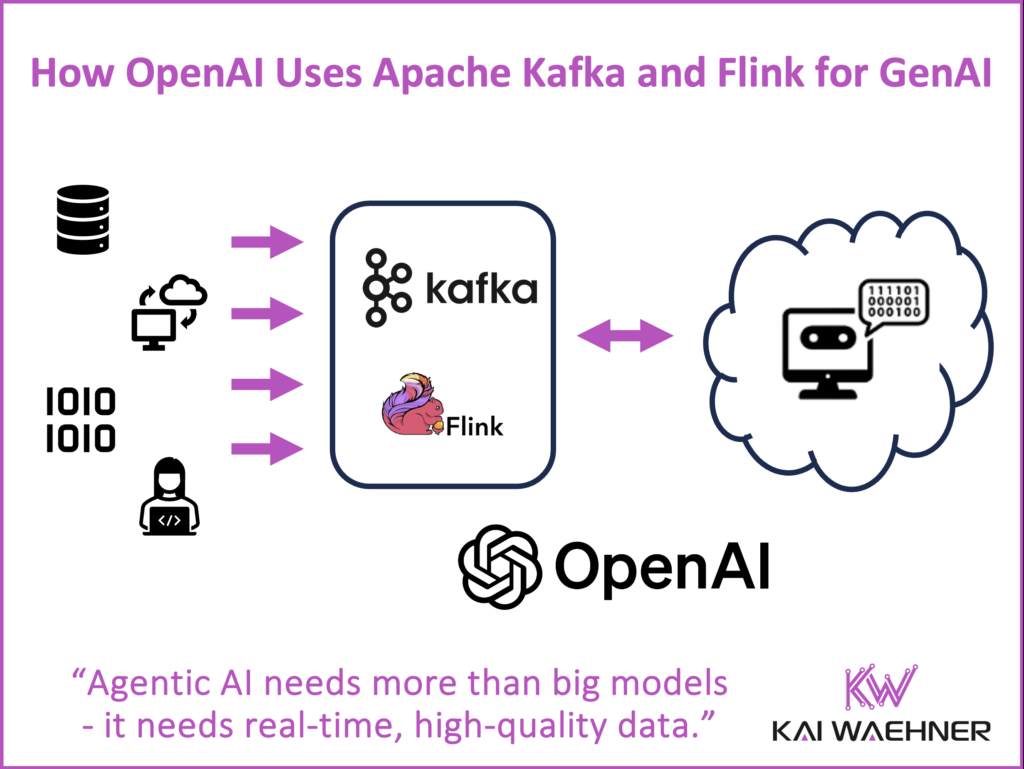
OpenAI pulled back the curtain at the Current 2025 conference in London on how it builds and operates the data streaming infrastructure behind its world-leading GenAI systems.
The message was clear: building powerful models like GPT-4.1 is only part of the equation. Equally critical is the ability to move, transform, and act on data in real time. And that’s where Apache Kafka and Apache Flink come in—powering the infrastructure behind ChatGPT, the user interface available via web and mobile apps.
This post summarizes how OpenAI uses Apache Kafka and Flink for large-scale streaming, how it handles Kafka at global scale, and why stream processing is indispensable for generative and agentic AI. While the three OpenAI talks at Current were highly technical—focused on architecture, infrastructure, and internal APIs—they offered rare insights into how real-time data streaming fuels innovation at one of the world’s most advanced AI companies.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various AI examples across industries.
What Is OpenAI?
Unless you’ve been living under a rock—or far behind the moon—you’ve heard of OpenAI. The company behind ChatGPT, DALL·E, and Codex has reshaped how the world thinks about artificial intelligence.
But OpenAI is more than just clever chatbots and image generators. It’s a full-stack AI powerhouse. The company builds cutting-edge foundation models, provides fine-tuning tools and APIs (like GPT-4 and GPT-4o), and delivers enterprise-grade infrastructure—all running on Microsoft’s Azure cloud.
As its user base and model complexity grow, OpenAI needs infrastructure that moves and reacts at the speed of data. This is why the company is doubling down on real-time stream processing with Apache Kafka and Flink.
Fun Fact: I also trained the latest version of my personal chatbot K.AI using OpenAI’s custom GPT builder.
Apache Kafka and Flink: The Event-Driven Foundation for GenAI and Agentic AI
Generative AI isn’t just about building a big Large Language Model (LLM). It’s about creating a data flywheel—feeding models with (near) real-time data to improve accuracy, personalization, and responsiveness.
Here’s why Kafka and Flink are foundational for that:
- Apache Kafka handles the ingestion, delivery, and storage of massive volumes of event data from services, users, and internal systems—across multiple cloud regions.
- Apache Flink processes that data with low latency, adds stateful transformations, and supports continuous feedback loops and safety mechanisms for real-time AI operations.
This real-time loop helps many companies to improve batch and even online model training, experimentation, inference coordination, and many other use cases. As outlined in my blog post about TikTok’s Recommendation Algorithm leveraging Kafka and Flink for Online Model Training, these same principles are being adopted across industries.
Current 2025 Recap: OpenAI’s Technical Sessions about Data Streaming with Kafka, Flink and GenAI
At Current 2025, OpenAI revealed the inner workings of its data streaming architecture—showcasing how Apache Kafka and Flink support Generative AI at scale through advanced stream processing, simplified Kafka consumption, and resilient infrastructure practices.
Check out the links below if you want to watch the entire presentation recordings.
1. Building Stream Processing Platform at OpenAI with Kafka and Flink
This session by Shuyi Chen outlined OpenAI’s Kafka and Flink setup—running PyFlink in production with custom enhancements to scale with their unique needs.
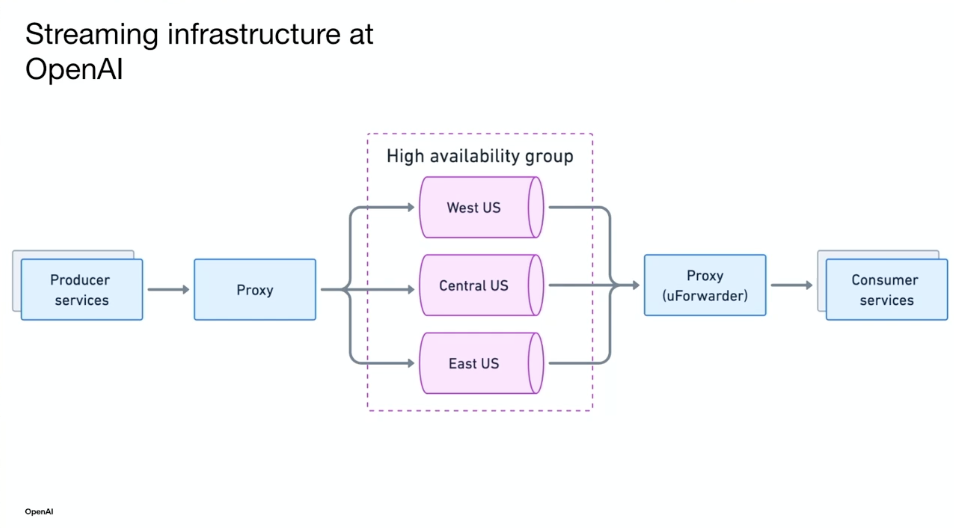
Key takeaways:
- PyFlink is extended to process training and experiment data.
- Flink Kubernetes Operator supports local deployment and lifecycle control.
- A multi-region Flink architecture helps manage failover and replication.
- Kafka is tightly integrated as both source and sink in the stream processing flow.
The focus is not batch analytics, but near-real-time signal processing—fueling OpenAI’s model feedback loops.
2. Taming Kafka Complexity: Kafka Forwarder
The talk by Jigar Bhati explored Kafka Forwarder: OpenAI’s solution to simplify Kafka consumption across teams and clusters.
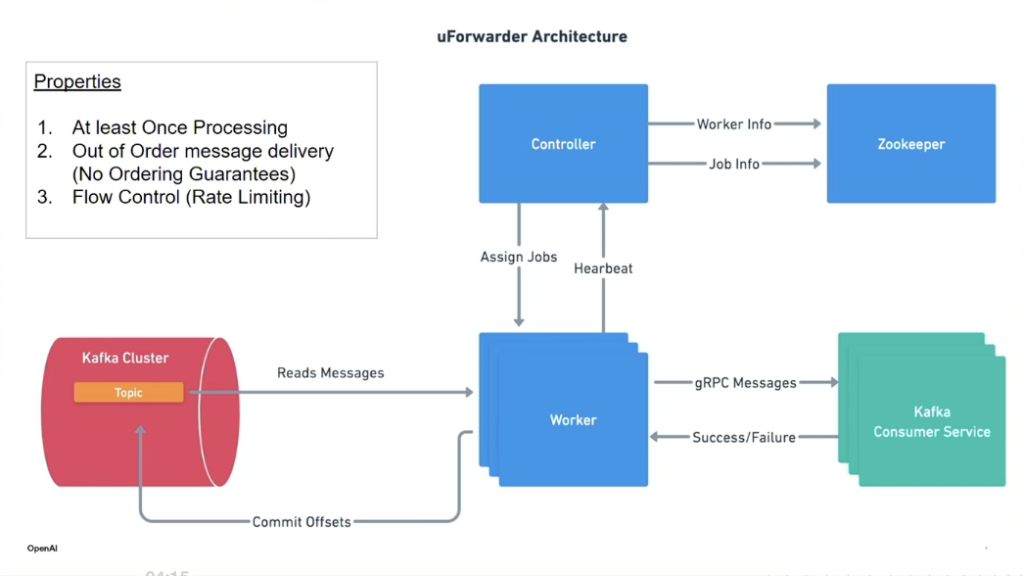
Highlights:
- Converts pull-based Kafka consumption into a gRPC-based push model.
- Simplifies partition management, retries, DLQs, and offset handling.
- Pushes messages to downstream services in Databricks and beyond.
- Enables decoupled, scalable consumption with reduced operational burden.
The architecture leverages Uber’s uForwarder, a proxy that transfers data from Kafka to message consumers through the RPC protocol.
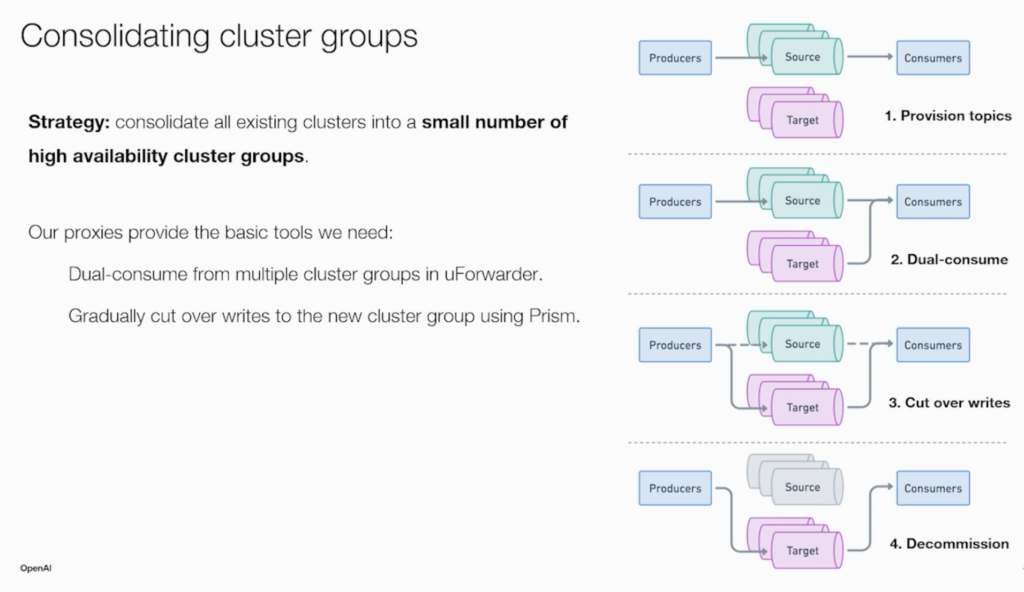
3. Kafka Migrations Without Downtime
Changing Kafka clusters is a mission-critical scenario at OpenAI. The session “Changing Engines Mid-Flight” by Adam Richardson and Nat Wilson covered:
- Multi-cluster architecture patterns with Kafka and Flink
- Best practices for consumer rebalancing and producer redirection
- Lessons learned from global migrations at production scale
- Tools and patterns for safe upgrades and region failovers
The following architecture shows OpenAI’s migration strategy to consolidate Kafka clusters during the migration:
Why It Matters: Data Streaming Powers Generative AI and Agentic AI
The key insight from these sessions is that large AI models are useless without the right data at the right time. Agentic AI—where autonomous agents act, learn, and adapt—relies even more on timely context and feedback.
Data streaming with Apache Kafka and Flink provides:
- Fresh training and evaluation data
- Infrastructure for experimentation
- Real-time ingestion and decision-making
- Scalable coordination across model pipelines and applications
Without Kafka and Flink, none of this happens fast enough for Generative AI and Agentic AI.
OpenAI’s Hidden Backbone of GenAI: Apache Kafka and Flink Behind the Curtain
OpenAI is not just pushing AI forward—it’s building the infrastructure to support it. At the heart of that effort is a scalable data streaming platform based on Apache Kafka and Flink. The company’s engineering talks at Current 2025 revealed the scale, complexity, and importance of data streaming for Generative AI and Agentic AI at the highest levels.
For every organization exploring AI adoption, the lesson is the same: if you want smarter systems, start with better data infrastructure.
To learn more about how Kafka and Flink enable online learning, feedback loops, and low-latency AI, read my blog post on TikTok’s real-time AI architecture.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various AI examples across industries.