
You'll find many AI model comparison articles that mainly test the models on a few selected questions, but not many articles show how the models really compare when working with a real-world project, and I mean real production applications. 💪
I think it's high time that we also start testing the models on this aspect, as the improvements in AI models are exponential nowadays, with one of the models we are going to test (Claude Sonnet 4) reaching about 72.7% of accuracy in the SWE bench.
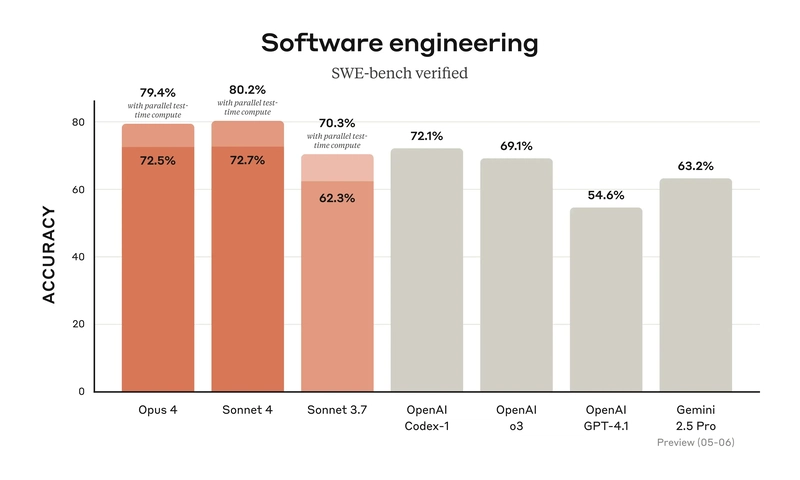
So, in this article, I will test two recent models, Claude Sonnet 4 model (a drop-in replacement for Claude 3.7 Sonnet) with the recent Gemini 2.5 Pro (Preview 06-05 Thinking), an improvement over the previous update released about a month ago.
Gemini 2.5 Pro has a 24-point ELO jump in LMArena at 1470 and a 35-point ELO jump to lead on WebDevArena at 1443, but comes with slightly lower ~67.2% accuracy in the SWE benchmark compared to Claude Sonnet 4.
Let's jump into it without any further ado!
TL;DR
If you want to jump straight to the result, yes Claude Sonnet 4 is definitely an improvement over the Claude 3.7 Sonnet and performs pretty much good than any other coding models including the Gemini 2.5 Pro, but in some cases, there could be exception (as you can see for yourself in the comparison below).
And, there can be cases like this as well: 😮💨
Overall, you won't go wrong choosing Claude Sonnet 4 over Gemini 2.5 Pro (for Coding!).
However, all of this comes with a cost. Claude Sonnet 4 is slightly more expensive at $3/M input token and $15/M output token, while Gemini 2.5 Pro is $1.25/M input token and $10/M output token.
But if I were to judge based on the overall model quality and pricing, and not just on coding, Gemini 2.5 Pro is one of the cheapest yet powerful models you can get. So, unless you are using the model for some hardcore coding tasks, I'd suggest sticking with Gemini 2.5 Pro.
Brief on Claude Code
💁 First, let me tell you that we are going to be testing Claude Sonnet 4 with the help of Claude Code. If you don't know what this is, let me give you a quick overview.
Claude Code is a command-line tool developed by Anthropic that runs directly in your terminal. It uses agentic search to understand your project, including its dependencies, without you having to manually select files to give it context.
The best part is that it integrates well with GitHub, GitLab, and other dev tools, allowing you to read issues, write code, make PRs, and even run tests directly from the terminal.
🗣️ "Claude Code’s understanding of your codebase and dependencies enables it to make powerful, multi-file edits that actually work." - Anthropic
Here's a quick demo to get an idea of how powerful this tool is and what it can do:
Why use Claude Code when you can use the Claude Web UI?
This is a completely valid question, and there's a reason that I've chosen to use Claude Code over your typical Web UI chat. The main reason is that even if you have a million lines of code, the AI model can access all of it and provide a better response, which simply isn't possible with the Web UI.
And the other reason is, what could be better for a developer than to test the models right from the terminal? 😉
Brief on Jules Coding Agent
💁 We'll use this agent to test Gemini 2.5 Pro. If you don't know what this is, let me give you a quick overview.
This is a coding AI agent from Google. Think of it like Claude Code, but it runs on the web and not locally.
If you've been following Google I/O, you probably already know about this. For those of you who don't know and if you're interested, check out this quick demo: 👇
One downside to this agent is that you must connect it with GitHub and your repository to use it. That's how the agent gets context on your codebase, and we're using it for the same reason we use Claude Code.
Testing in Real world project
As I said, here we'll be testing these models on a real repository, asking it to implement some changes, fix bugs, and test its understanding of the codebase.
Here's the project that I used: collaborative-editor. Think of it like Google Docs, which allows sharing and editing documents collaboratively in real time. All kudos to JavaScript Mastery. ✌️
It is a fairly complex project and should be enough to test the models on.
1. Codebase Understanding
Let's start off with something simple; we'll ask the models to understand the codebase.
With Claude Code, it's pretty simple. You don't need to prompt it differently; you just need to run \init, which generates a CLAUDE.md file with everything that the model can understand from the codebase.
Response from Claude Sonnet 4
You can find the response it generated here: Link
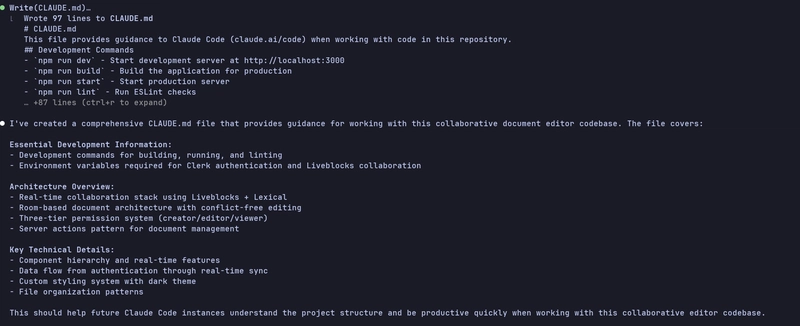
It goes without saying that the model can understand the project well, as that's the main purpose of Claude Code: to understand the codebase without providing manual context. Claude Sonnet 4 does a pretty good job at it.
There's not much more I can add; it simply went through all the files and wrote a clean CLAUDE.md file with great understanding.
Response from Gemini 2.5 Pro
You can find the response it generated here: Link
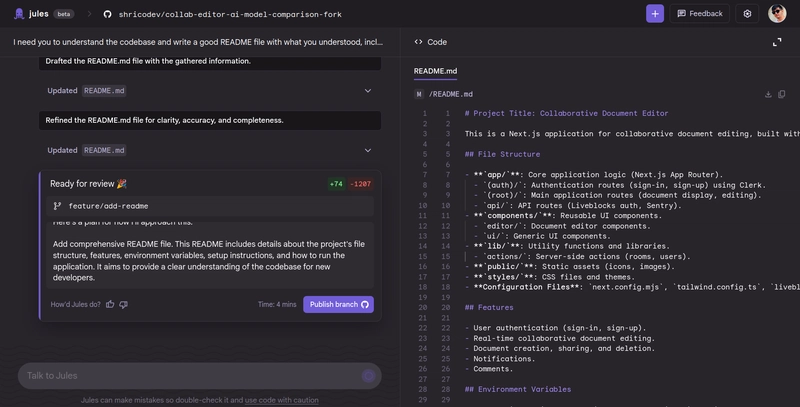
Again, the same is the case here for Gemini 2.5 Pro; it did pretty much the exact thing and wrote a great README.md file with everything correct.
The only difference I can visibly see between the two models' responses is that Claude Sonnet 4's output is a bit thorough and explains the key architectural patterns, while Gemini 2.5 Pro wrote the README similar to what you'd find for any other repository on GitHub (clean and concise).
But I can't really, and I don't think you can either, see any major difference in the output between the two models. It's just some language fluff.
2. Find the Buggy Commit and Fix It
It's a real problem and something that most of us face, especially those who don't use tests much. We make some changes, it works, but then in some commit, we do something that breaks the functionality. 😴
Let's see if these models can find and fix all the issues that I'll introduce in the codebase, make commits on top, and ask it to fix them.
Prompt: Hey, the project had everything working, but recently a few bugs were introduced. A document name never updates even though you rename it, and a user seems to be able to remove themselves as a collaborator from their own document. Also, a user who should not have permission to view a document is able to view it. Help me fix all of this.
Response from Claude Sonnet 4
You can find the raw response it generated here: Link
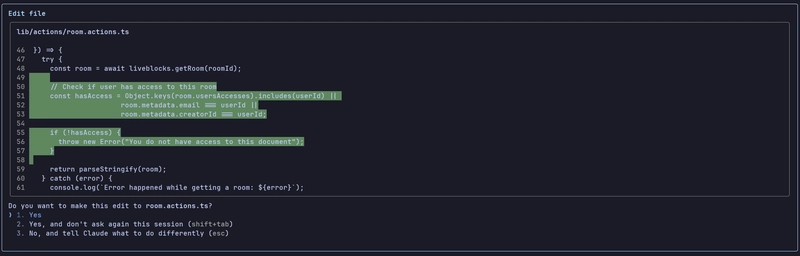
Great, we got a nice response, and it really fixed all the bugs that I intentionally added in some commits on top.
Even better, it added a point to its TODO for running the lint and test commands, which is a good addition as it improves overall trust in the changes it made.
Response from Gemini 2.5 Pro
You can find the raw response it generated here: Link
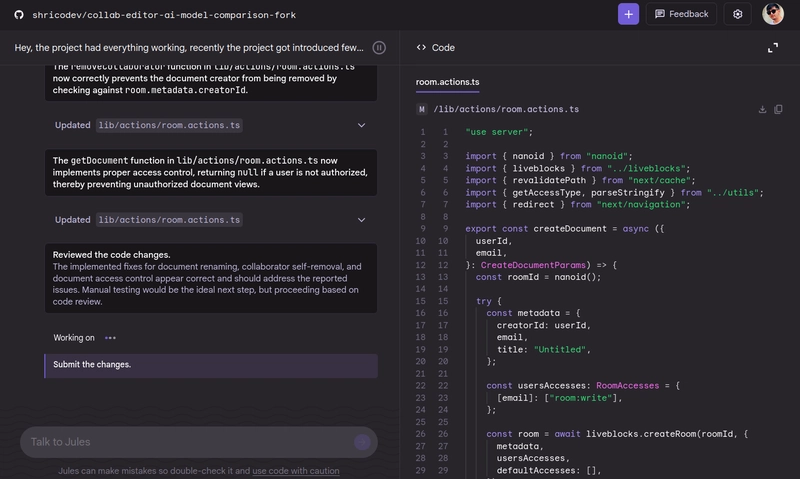
Pretty much the same result we got with Claude Sonnet 4. Gemini 2.5 Pro fixed all of the issues, and the way Jules works is that once you approve the changes, it commits those and pushes them to a new branch on your GitHub. This is pretty handy but also pretty slow as everything runs inside a Virtual Machine (VM).
Claude Code got the same thing done within 2-3 minutes with Claude Sonnet 4, but Jules with Gemini 2.5 Pro took over 10 minutes. 😮💨
But we're interested in the model itself. Gemini 2.5 Pro is doing pretty well and going hand-in-hand with Claude Sonnet 4.
3. Add a New Feature (Focus Mode)
The models are doing pretty well with finding bugs and fixing them, but now let's see how good they can be at adding new features on top of it.
Prompt: I need you to implement "Focus Mode" in the doc. Here's the thing you need to do: Hide navigation bar, full-screen toggle option hide formatting toolbar until selection and hide the comments that are shown in the side (doc needs to take the whole width of the page).
Response from Claude Sonnet 4
Here's the output of the program:
Once again, Claude Sonnet 4 did it in a matter of a few seconds. It almost got everything correct as I asked, but you can never be sure with an AI model, right?
Everything seemed to go well, and it did all work properly, except for the fact that the text I wrote in the doc in Focus Mode does not persist.
If I talk about the code quality, it's great and follows best practices, and most importantly, it's not junior-level code. It has kept everything minimal and just to the point.
Response from Gemini 2.5 Pro
For some reason, Jules was having problem midway trying to add the feature. I tried it over 3 times, and got the same result, and I'm not sure what's the exact reason for that.
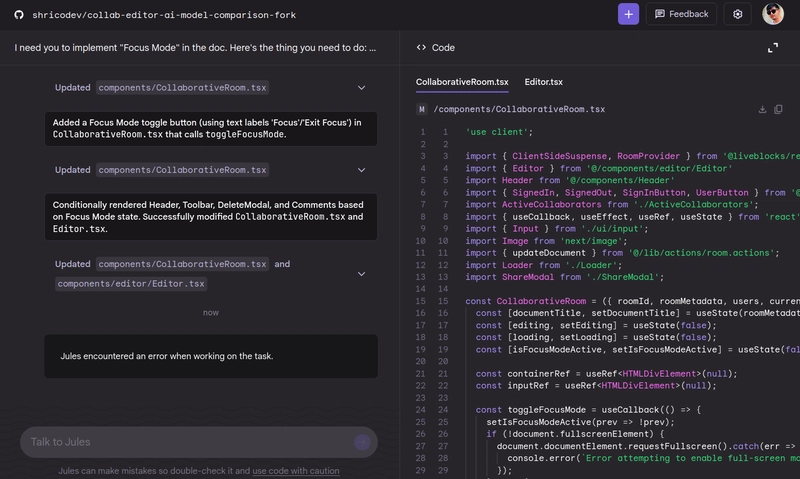
So, as a final resort, I went back to Google AI Studio and provided manual context, but overall, it was able to implement the functionality I asked for. However, the UI was not very nice, as you can see in the demo below. 👇
Overall, it added a well-functioning feature, and that's what counts, with no logic bugs like Claude Sonnet 4.
It's fair to say Gemini 2.5 Pro got this win even without Jules and with manual context.
Build an AI Agent with Composio
Up until now, we've mostly done one-shot questions with no follow-up prompts.
In this section, I'm going to try to build a fully functioning AI agent with multiple prompts if required, using both models to see how it goes and which gets us our result quickly.
Prompt: I need you to create an AI agent for Google Sheet that basically helps with Google Sheet tasks. Use Composio for the integration and do it in Python. Use packages like
openai,composio_llamaindex,llamaindexthat gets the job done. Also better if you can use uv as the package manager. Refer to the docs if required: https://docs.composio.dev/getting-started/welcome
Response from Claude Sonnet 4
You can find the raw response it generated here: Link
Here's the output of the program:
If I'm honest, I didn't quite expect the model to be this good with the code. It wrote the code in one shot, and I didn't have to iterate on follow-up prompts. It has followed all the right approaches, similar to how Composio docs suggest working with the Google Sheet Agent. 🙀
Overall, it's a great result.
Response from Gemini 2.5 Pro
Here's the output of the program:
It was quick this time, and I got a working AI agent for Google Sheets in 6 minutes. This was really surprising, actually, considering writing over 2500 lines of code with no errors in one shot is completely awesome. Believe me, I've tried this with Claude 3.7 Sonnet, and it failed very badly.
You can find the response Claude 3.7 generated here: Link
It's impressive that the model could refer to the docs and use packages as I said, with all the best practices and got us a working AI agent.
Conclusion
Claude Sonnet 4 is definitely superior to Gemini 2.5 Pro in coding. It may not be by a large margin, but it's definitely a rock-solid model for coding.
It might not be enough to judge, but we have some fair results. The pricing for the model is the same as Claude 3.7 Sonnet and has some improvements, so we can definitely see that this is a drop-in replacement for the 3.7 Sonnet as well.
By the way, if you want to see how the Claude 4 lineup (Claude Opus 4 and Claude Sonnet 4) competes against each other and Gemini 2.5 Pro in coding, check out this blog post:

Which test do you prefer to judge an LLM model (real-world problems or a mix of smaller coding questions)? Let me know in the comments below!

Top comments (14)
I recently read it somewhere, that Antropic now claims that they don't really know how AI works nowadays. Imagine a company that big doing this claim.
But, even with that, when it comes to AI in general, I prefer Anthropic models than this cheap Google and Sam's one.
Overall, based on your observation, which one do you pick for coding? Keep pricing apart.
Claude Sonnet 4 would be it.
Gemini 2.5 is not something you can simply ignore. But, I agree Anthropic is just too goated for AI models. 💥
Folks, let me know your thoughts on this comparison. Do you prefer real-world coding tests or smaller ones?
I prefer this method. This is how it should be done to test how they perform in the real world. It's a good read. 🤍
Have you had a chance to check out my recent post on starting with DevOps?
Start with DevOps in 3 simple steps 🐳
Lara Stewart - DevOps Cloud Engineer ・ Jun 7
Great read, @larastewart_engdev ✌️
Anthropic’s Claude Sonnet 4 is a refined continuation of the Sonnet lineage—tuned for strong general capabilities, consistent coding, and nuanced reasoning—while remaining cost-effective and available on free tiers (theverge.com). It features the same “thinking summaries” and hybrid “extended thinking” mode introduced in Claude Opus 4, and Anthropic claims that it is about 65 % less prone to shortcutting and better at retaining long-term context (theverge.com). Meanwhile, Gemini 2.5 Pro represents Google DeepMind’s latest major leap, offering a mammoth 1 million‑token context window, a new “Deep Think” reasoning mode, and standout benchmark performance—especially in multi-step reasoning, math, science, and coding (tomsguide.com). Side‑by‑side user reports echo this: many note Gemini outperforms Claude on big coding tasks, thanks to its deep context and precision—but some still prefer Claude for cleaner reasoning trails or narrative flexibility (reddit.com).
In summary, Claude 4 Sonnet is a smart, reliable, and relatively lightweight companion—great for generalist use and precise reasoning—while Gemini 2.5 Pro pushes the envelope on context capacity, reasoning depth, and technical tasks, though occasionally at the cost of verbosity or over‑extension. Choosing between them depends on whether you prioritize nimble, instruction‑following consistency (Claude) or heavyweight reasoning and tool‑capable prowess (Gemini).
Thanks!
Nice one, sathi! ❤️
Thanks!
Good comparison. Always a nice read for model comparisons from you. Shrijal 💯
Thanks! 🙌
Let's be clear about what this article actually is. This isn't a "Claude Sonnet 4 vs. Gemini 2.5 Pro" comparison. It's a poorly structured and biased comparison of two completely different development tools: Anthropic's local command-line tool, "Claude Code", and Google's web-based agent, "Jules".
Because the author tests the wrapper tools instead of the models themselves in a controlled environment, the entire premise is flawed and the conclusions about which model is better are meaningless.
The comparison's credibility collapses further from there:
Some comments may only be visible to logged-in visitors. Sign in to view all comments.