
Originally shared here:

Qwen 3 Benchmarks, Comparisons, Model Specifications, and More
Details about Qwen3; including benchmarks and comparisons, model sizes and specifications, and more
bestcodes.dev
Qwen3: Alibaba's Latest Open-Source AI Model
Qwen3 is the latest generation of large language models (LLMs) from Alibaba Cloud. Built by the team behind the Tongyi Qianwen series (通义千问), this release brings serious power and flexibility, packed into an Apache-2.0-licensed, open-source package.
Released on April 29, 2025, Qwen3 comes in eight sizes, including both dense models (from 600M to 32B parameters) and Mixture-of-Experts (MoE) giants, like the flagship Qwen3-235B. These MoE models activate only a small slice of their total parameters at a time (like 22B out of 235B), so you get high performance without insane compute requirements.
Let's dive into some of the key features.
Model Sizes and Options
Here's a quick look at what you can choose from:
| Model | Type | Params (Total / Active) | Max Context |
|---|---|---|---|
| Qwen3-235B-A22B | MoE | 235B / 22B | 128K |
| Qwen3-30B-A3B | MoE | 30B / 3B | 128K |
| Qwen3-32B | Dense | 32B | 128K |
| Qwen3-14B | Dense | 14B | 128K |
| Qwen3-8B | Dense | 8B | 128K |
| Qwen3-4B | Dense | 4B | 32K |
| Qwen3-1.7B | Dense | 1.7B | 32K |
| Qwen3-0.6B | Dense | 0.6B | 32K |
All models are licensed under Apache 2.0, so you can use them in commercial apps without worrying about legal issues.
Benchmarks and Comparisons
The benchmarks below evaluate Qwen3 with reasoning enabled.
Qwen3-235B (the flagship model) leads on the CodeForces ELO Rating, BFCL, and LiveCodeBench v5 benchmarks but trails behind Gemini 2.5 Pro on ArenaHard, AIME, MultilF, and Aider Pass@2:
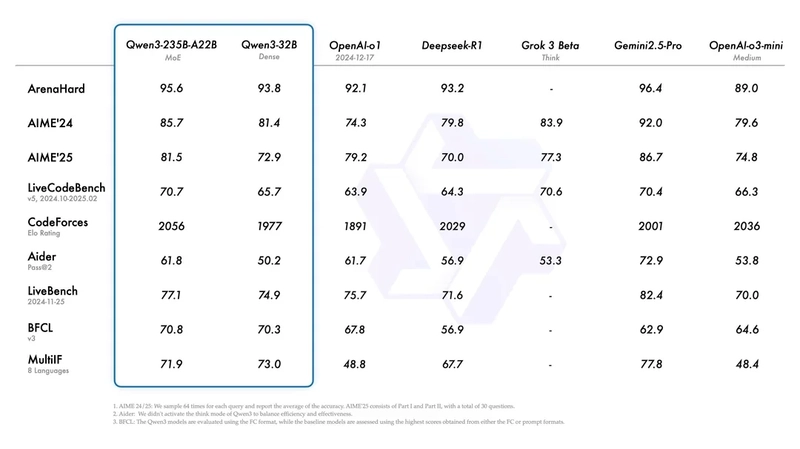
Compared to open-source and less bleeding-edge models, Qwen3-30B (a smaller model) excels in both speed and accuracy. It is outranked only by QwQ-32B, another Alibaba model, in the LiveCodeBench and CodeForces benchmarks as well as GPT-4o in the BFCL benchmark:
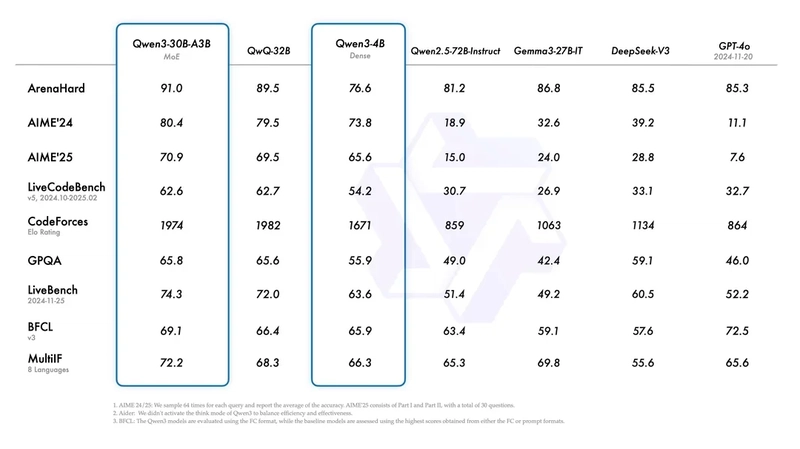
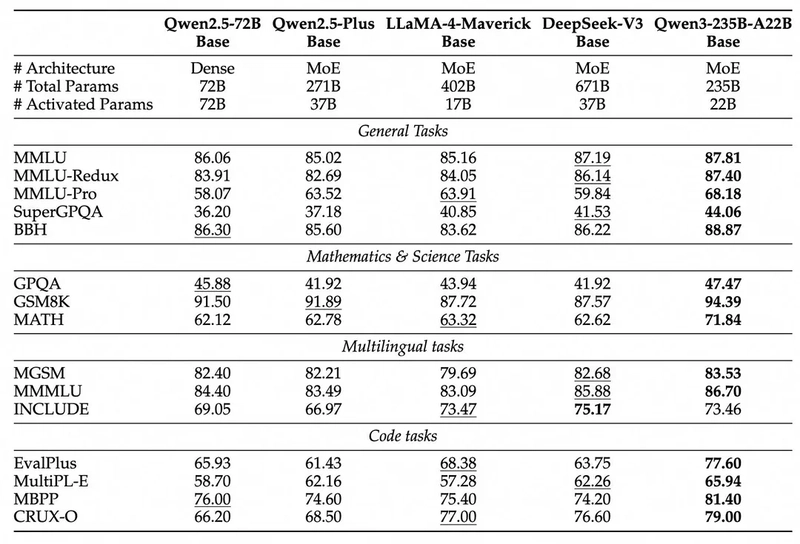
Below, despite being the second-smallest model, Qwen3-235B outranks all models on all benchmarks, excepting DeepSeek v3 on the INCLUDE Multilingual tasks benchmark.
What's New in Qwen3?
Dual "Thinking" Modes
This is one of the coolest features: Qwen3 can switch between "thinking" mode and "non-thinking" mode. Thinking mode is for deep reasoning, like chain-of-thought answers for complex tasks. Non-thinking mode skips the fluff and gives you fast, concise responses.
So, depending on the prompt or task, Qwen3 can choose to think deeply or just get to the point. That means better speed when you want it, and better depth when you need it.
MoE for Smarter Scaling
The MoE (Mixture-of-Experts) architecture is how Qwen3 pulls off those giant parameter counts. Instead of using all the parameters every time, it activates only a few "experts" per token. For example, Qwen3-235B uses just 22B active parameters at once, so it's much cheaper to run than you'd expect for its size.
It's a smart way to scale up without blowing your budget on GPUs.
Trained on 36 Trillion Tokens Across 119 Languages
Qwen3 was trained on a massive dataset of about 36 trillion tokens, including web data, books, PDFs, and synthetic code/math generated by earlier Qwen models. It now understands 119 languages and dialects, making it one of the most multilingual models out there.
Whether you're working in English, Chinese, or a low-resource language, Qwen3 is probably ready to help.
Smarter Agents and Better Coders
Qwen3 wasn't just trained to talk. Alibaba also focused on tool use, planning, and coding, making this generation much better at things like:
- Writing and debugging code
- Solving math and logic problems step-by-step
- Acting as an AI agent that can use tools or browse the web
In fact, even the Qwen3-4B reportedly outperforms some earlier 72B models on tasks like programming.
Getting Started
You can grab the models from:
You'll also find detailed guides, tokenizer info, and fine-tuning instructions on their GitHub page.
Final Thoughts
Qwen3 is one of the best open LLMs available right now. Of course, that will probably change pretty soon at the rate new models are being released.
Thanks for reading!
BestCodes
Some portions of this article are AI generated.

Top comments (18)
kinda insane how fast this stuff moves - i'm always trying to keep up but dang, it changes every week
Yep, Phi 4 Reasoning came out right after I wrote this, and now I have to do one on it 🤭
Qwen3 is... highly overrated!
Here'a my case.
I wanted to build some visuals in code based on a description of the visual. Qwen3 required many many many iterations before it was able to present me something that was - with a lot of squinting and frowning - barely what i meant for it to build.
Then i tried the exact same thing with the exact same prompts in Gemini 2.5 pro. It did a near perfect job in a single shot and only required a few more minor revisions to make it exactly as i intended.
Now does that mean Qwen3 is bad and Gemini 2.5 Pro is good? Yes and no.
For specific requests Qwen3 is probably on par or definitely able to compete. But when it actually needs to reason about the thing you ask it to do then it's more accurate to describe it's "cognitive skills" as a junior student whereas the reasoning from Gemini is truly bordering final exam student level. Meaning they both are good models, but Gemini is just better at "thinking" and thus giving better results where it needs that skill.
Gemini 2.5 Pro isn't open source. I'm excited about Qwen3 because it is one of the top performing open source models right now 🙂
Agreed! And i use Qwen happily :) Well, still the 2.5 coder one, it's awesome!
My point was more that it's thinking ability is.. ok at best.
I haven't tried it yet but i assume Llama 4 is better. And deepseek r1 definitely is better, that i did try just not on this example case.
Yeah, the problem with models like DeepSeek R1 and Llama 4 is that they are huge and usually have to run on a remote server or a special device. CPU devices or typical laptops can't run them or run them really slow 🥲
Qwen 3 has a 0.6b variant which super nice because it can run locally even on very small or weak devices. The size to performance ratio with Qwen models is great.
Oh boy, you're hallucination :P
Think of these tiny models of a kid that has the potential to be at Einstein level but with a massive amount of amnesia (it forgot 90% of what it learned or more). It can talk and form sentences but the responses are mostly close to useless. It can do some simple things well but that's about it.
In my testing i found that anything below 3B (not just qwen, all these models out there) is mediocre at best. 3B itself being the transition point from where responses make leaps and bounds in terms of quality.
But tiny models have great value! Like recently AMD seems to be using tiny models to use their next token prediction as a sort of pre-prediction for a large model. The large one then just has to verify if it would've done that same prediction (which is apparently a lot cheaper then to predict) and then use it. It essentially means large models at the speeds of tiny models with the quality of the large one. Mind blowing, literally. AMD seems to be getting up to 4x tokens/sec from 7-8B models when a tiny models is used to pre-predict.
Yeah, it's not the greatest for facts, but for chatting or writing code it's pretty nice. The 4b and 30b Qwen3 models are also very impressive, especially for their size. The Qwen architecture is improving a lot too, so they require less and less memory to run!
LM Studio has an option to offset the main model with another one, so I've actually been using Qwen3 14B and 0.6B as secondary to gain ~2-3x speed gains without much of a difference. It's worth looking at! It leaves me enough headroom to run GLM-4-0414-9B as a Designer agent, and I throw on a tiny Text-Embedding (all-MiniLM-L6-v2) model and runs 24/7 on local compute.
It's good for the right task, and dramatically benefits from tool use, such as MCP servers. And what size model are you saying wasn't good? I hope you meant the largest 235B model at the very least (when comparing to a commercial model). I also find that one model is not the best on its own. Generally, "Architect" mode where you use one model as reasoner and another as coder (even if technically the same model), which based on aider benchmarks can improve output by ~20%. But the major takeaway is your workflow using a commercial solution vs open source will be different, that's expected because they figured everything out for you... so things just "work".
Some researchers have pruned the Qwen 3 30b model to 16b and will soon prune the 235b to 150b, which will make it much lighter and a higher performance/size ratio. It will be interesting to test that one.
Qwen 3 30b A3 and 14B are already at par with each other. They trade blows on Math and Coding, but within a margin of each other and are both pretty good at memory usage. I use 4bit quants though, as from my experience you only loose ~5%-15% accuracy and save 75% resources. And I'd be concerned with pruning producing highly domain specific models (which is fine if that's what you want). You should also look into mixed quants done by Unsloth, very promising... their findings show almost no quality/accuracy loss with 80% resource reduction with faster speeds. They got DeepSeek R1 671B to run in <20GB of VRAM.
Got any links?
Link to X post about the Qwen 3 prune:
x.com/kalomaze/status/191837896041...
And I have looked into the work Unsloth is doing a lot! I was using the Unsloth gemma-3 not long ago and all the work over there is very impressive.
Fair (even though MCP isn't even possible on the released models). Yes, i was comparing the largest model. It was on the Qwen site itself which should've been my best possible experience.
I've been using it free through Openrouter or smaller models locally (I'm split between 30B A3B and 14B, they seem very close). Might check their API out directly. I've had some promising luck setting up several models to automate processes, but a lot more work needs to be done. For one, you can use Task-Master MCP and tell the AI to build a robust debugging framework around the project with tests and verbose log everything, so it can solve its own problems. And you can make it "learn" by appending its knowledge base with lesions learned, text-embedding for context and faster search, etc. "Functional AGI" feels so close (to me just end-to-end AI without human interaction that can run 24/7 and self-improve). And to me, it's less about the model itself and the MoE + scaffolding around your AI system (the better the framework, the less capable the AI needs to be IMO).
And maybe I don't understand, but you should be able to use MCP's for anything you can get API access for. Unless you mean though their "Chat" counterparts, which I mostly only use now for deep research.
chat.qwen.ai/
MCP is grayed out.
It does seem the model itself does support it as it's plain there in the description on huggingface: huggingface.co/Qwen/Qwen3-235B-A22B
I don't really know how to use it yet, i haven't played with MCP yet though i guess with all the hype around it i'll probably give it a try soon. The thing that stops me is the extra fuss i have to go through (using open-webui) to get that mcp stuff running. I need a proxy for it apparently, yeah just haven't had the interest yet to dig into it.
I'm also using openrouter (and hooked it into open-webui). It's nice being able to pick from hundreds of models right there! And local is on the list too if you have models locally.
The Qwen chat is just an interface for the model. Even the official interfaces for models aren't always the best.
Also, MCP isn't a thing that only some models support (though some might be more optimized for it), it's just a protocol that models can use.
good info :)