Preface
Function Calling Schema
Pseudo Code
import { Agentica, assertHttpController } from "@agentica/core";
import typia from "typia";
const agent = new Agentica({
controllers: [
assertHttpController(
await fetch(
"https://shopping-be.wrtn.ai/editor/swagger.json",
).then(r => r.json())
),
typia.llm.application<ShoppingCounselor>(),
typia.llm.application<ShoppingPolicy>(),
typia.llm.application<ShoppingSearchRag>(),
],
});
await agent.conversate("I wanna buy MacBook Pro");LLM function calling schema must be built by compiler, without any duplicated code.
@agentica is specialized in LLM (Large Language Model) function calling. Complex agent workflows and graphs required in conventional AI agent development are not necessary in @agentica. @agentica will do everything with the function calling. Therefore, the most important thing in @agentica based development is, how safely and efficiently build the LLM function calling schema.
By the way, what if a person writes a function calling schema by hand and makes a mistake? It will break the entire AI agent system, because the LLM function calling would never be successful with the wrong schema. For example, in the case of a traditional backend development, if a backend developer takes a mistake in the API documentation, the frontend developer (human) can intuitively avoid it. However, AI never forgives such mistakes.
To prevent such human mistakes, the LLM function calling schema must be constructed by the compiler. Also, it must not require any duplicated code. I call this concept as “Compiler Driven Development”.
TypeScript Class
TypeScript Source Code
import { ILlmApplication } from "@samchon/openapi";
import typia from "typia";
import { BbsArticleService } from "./BbsArticleService";
const app: ILlmApplication<"chatgpt"> = typia.llm.application<
BbsArticleService,
"chatgpt"
>();
console.log(app);Use typia.llm.application<Class, Model>() function.
@agentica is guiding to use typia.llm.application<Class, Model>() function when constructing a function calling schema for a TypeScript class method. The compiler library typia will analyze the source code for the target class type Class, and automatically create an LLM (Large Language Model) function calling schemas.
If you visit above 💻 Playground Link or click the “Compiled JavaScript” tab, you can see how the compiler changes your class type (BbsArticleService) to LLM function calling schemas. LLM function calling schema must be constructed by compiler without any duplicated code like this way. This is the concept “Compiler Driven Development” what I am saying.
For reference, @agentica is the only one framework that supporting TypeScript class function calling. And typia is the only one library which can create LLM function calling schema from the TypeScript class type. Regardless of whether you follow the “Compiler Driven Development” rule or not, this is the only way to call a function for a TypeScript class method in AI agent.
Backend Development
Java/Kotlin Spring
@ExtendWith(RestDocumentationExtension::class, SpringExtension::class)
@SpringBootTest
class SampleControllerTest {
private lateinit var mockMvc: MockMvc
@BeforeEach
internal fun setUp(context: WebApplicationContext, restDocumentation: RestDocumentationContextProvider) {
mockMvc = MockMvcBuilders
.webAppContextSetup(context)
.apply<DefaultMockMvcBuilder>(
MockMvcRestDocumentation.documentationConfiguration(
restDocumentation
)
).build()
}
@Test
fun getSampleByIdTest() {
val sampleId = "aaa"
mockMvc.perform(
get("/api/v1/samples/{sampleId}", sampleId)
)
.andExpect(status().isOk)
.andExpect(jsonPath("sampleId", `is`(sampleId)))
.andExpect(jsonPath("name", `is`("sample-$sampleId")))
.andDo(
MockMvcRestDocumentationWrapper.document(
identifier = "sample",
resourceDetails = ResourceSnippetParametersBuilder()
.tag("Sample")
.description("Get a sample by id")
.pathParameters(
parameterWithName("sampleId")
.description("the sample id"),
)
.responseFields(
fieldWithPath("sampleId")
.type(JsonFieldType.STRING)
.description("The sample identifier."),
fieldWithPath("name")
.type(JsonFieldType.STRING)
.description("The name of sample."),
),
),
)
}
}Swagger/OpenAPI document must be composed by compiler.
Looking at backend development ecosystem of traditional, it is not easy to building the Swagger/OpenAPI document. Most of traditional languages and frameworks are guiding to write the Swagger/OpenAPI document by hand.
Considering the use case of backend servers in the LLM (Large Language Model) function calling of AI chatbot, most of them would be enterprise level applications that generally have a large number of API functions. Therefore, the stability and the efficiency of mass production are much more important than the class function calling case.
By the way, how the human cannot take any mistake on the documentation? In the traditional development ecosystem, if a backend developer takes a mistake in the API documentation, the frontend developer (human) can intuitively avoid it. However, AI is not. AI never forgives such mistakes when performing the LLM function calling. The function calling would never be successful with the wrong schema.
To overcome such human mistakes, @agentica recommends to adapt new era’s backend framework like FastAPI or NestJS. These frameworks are supporting the Swagger/OpenAPI document generation by the compiler. They don’t require human’s hand-writing the JSON schema.
Legacy Backend Development
Java/Kotlin Spring Framework
@ExtendWith(RestDocumentationExtension::class, SpringExtension::class)
@SpringBootTest
class SampleControllerTest {
private lateinit var mockMvc: MockMvc
@BeforeEach
internal fun setUp(context: WebApplicationContext, restDocumentation: RestDocumentationContextProvider) {
mockMvc = MockMvcBuilders
.webAppContextSetup(context)
.apply<DefaultMockMvcBuilder>(
MockMvcRestDocumentation.documentationConfiguration(
restDocumentation
)
).build()
}
@Test
fun getSampleByIdTest() {
val sampleId = "aaa"
mockMvc.perform(
get("/api/v1/samples/{sampleId}", sampleId)
)
.andExpect(status().isOk)
.andExpect(jsonPath("sampleId", `is`(sampleId)))
.andExpect(jsonPath("name", `is`("sample-$sampleId")))
.andDo(
MockMvcRestDocumentationWrapper.document(
identifier = "sample",
resourceDetails = ResourceSnippetParametersBuilder()
.tag("Sample")
.description("Get a sample by id")
.pathParameters(
parameterWithName("sampleId")
.description("the sample id"),
)
.responseFields(
fieldWithPath("sampleId")
.type(JsonFieldType.STRING)
.description("The sample identifier."),
fieldWithPath("name")
.type(JsonFieldType.STRING)
.description("The name of sample."),
),
),
)
}
}In the existing backend development ecosystem, as API documents are written by hands, it is very difficult, dangerous and not suitable for Agentic AI agent development. As I am a Korean, I will talk about this story within framework of the Korean backend ecosystem.
In Korea, Java takes about 90% of the backend development ecosystem of major IT companies (experience of other languages are not recognized in Korea). And in the Java ecosystem, most of them have adopted Spring Framework , and force to use Spring RectDocs for the API documentation purpose. Even when generating Swagger/OpenAPI documents, company policy dictates to convert from the RestDocs.
And in the RestDocs, you have to write the API documents manually by your hands. As you can see from the above example code, you have to write the API endpoint ("/api/v1/samples/{sampleId}") by yourself, and also must write the schema types (fieldWithPath("name").type(JsonFieldType.STRING).description("The name of sample.")) manually. If you take some mistakes on the documentation, it only can be caught by the runtime level test functions. The mistake never can be caught in the compilation level, so that API documentation is extremely hard work for backend developers.
And in most cases, backend developers in Korea have roles divided within the team, with those who develop the main program, those who write test code, and those who write API documentation. And in most cases, the main program is developed by senior developers, and test programs or API documentations are shifted to the junior developers.
Hand writing the API documentation with extra schema definition of duplicated code. Do you think it is suitable for the new era of AI agent development? I think it is not. Java Spring Framework is not suitable for Agentic AI development.
I am not a backend dedicated developer and have never used Java/Spring, so I do not know this ecosystem in detail. I wrote this article based on company regulations and interviews with backend developers and technical blog articles of them.
And while researching information about Java’s OpenAPI documentation ecosystem, I suddenly had a question. Looking at Java Spring Framework, there is a way to build Swagger directly and there are annonations related to the Swagger documentation, so why use
RestDocs? Regarding this, the company regulations and senior backend developers are saying the same word even in their technical blogs.“Swagger is invasive to the operation code, and RestDocs is not”
This is probably the answer to why there is a division of main program developers, test developers, and documentation developers within the backend team. However, as I am not a developer in this ecosystem, so I cannot understand it exactly. If anyone knows more about this subject, please let me know the reason why.
References:
- https://techblog.woowahan.com/2597/
- https://toss.tech/article/tosspayments-restdocs
- https://helloworld.kurly.com/blog/spring-rest-docs-guide/#%EB%B0%8B%EB%B0%8B%ED%95%9C%EA%B2%8C-%EC%95%84%EC%89%AC%EC%9A%B0%EB%8B%88%EA%B9%8C-spring-rest-docs-%EC%97%90-swagger-%EB%A5%BC-%EB%84%A3%EC%96%B4%EB%B3%B4%EC%9E%90
- https://tech.kakaopay.com/post/openapi-documentation/
Php Laravel Framework
<?php
class BbsArticleController {
/**
* @OA\Post(
* path="/boards",
* tags={"BBS"},
* summary="Create a new article",
* description="Create a new article with its first snapshot",
* @OA\RequestBody(
* description="Article information to create",
* required=true,
* @OA\MediaType(
* mediaType="application/json",
* @OA\Schema(
* @OA\Property(
* property="title",
* type="string",
* description="Title of article",
* ),
* @OA\Property(
* property="content",
* type="string",
* description="Content body of article"
* ),
* @QA\Property(
* property="files",
* type="array",
* @QA\Items(
* @QA\Schema(
* @QA\Property(
* property="name",
* type="string",
* maxLength=255,
* description="File name, except the extension"
* ),
* @QA\Property(
* property="extension",
* type="string",
* nullable=true,
* maxLength=8,
* description="File extension. If no extension, then set null"
* ),
* @QA\Property(
* property="url",
* type="string",
* format="url",
* description="URL address that the file is located in"
* )
* )
* )
* )
* )
* )
* ),
* @OA\Response(response="200", description="Success"),
* @OA\Response(response="400", description="Fail")
* )
*/
public function create(Request $request);
}
?>In globally, Php seems like the major language of backend development ecosystem, and Laravel is the most popular framework in the Php language. By the way, when making a Swagger/OpenAPI document in the Php Laravel Framework, you have to write documentation comments like above with @OA tags hand manually.
This is the most horrible and dangerous way of building swagger documents I have ever seen. At this point, CDD (Contract Driven Development) advocated by OpenAPI Foundation seems better. Isn’t it the same thing as writing Swagger specs by hand as Php comments, versus writing Swagger documents by hand?
Researching it, I understood one thing. If you take mistake when writing the Swagger documentation comment, it never can be caught automatically as RestDocs case. And even just typo mistake like OAA\Respons() or QA\Proper(type='stringggg') never can be caught until actually opening the Swagger document. Unless RestDocs forces user to write a test program validating the operation and its schemas, the Laravel’s swagger generator does not any restriction, so that I could hear that no one of Php co-working client developer believes the Swagger document.
I can clearly say that, Php has the worst ecosystem for Super AI chatbot development. This is the most terrible solution I’ve ever seen.
Python Django Framework
from drf_spectacular.utils import extend_schema, OpenApiParameter, OpenApiExample
from drf_spectacular.types import OpenApiTypes
class AlbumViewset(viewset.ModelViewset):
serializer_class = AlbumSerializer
@extend_schema(
request=AlbumCreationSerializer,
responses={201: AlbumSerializer},
)
def create(self, request):
# your non-standard behavior
return super().create(request)
@extend_schema(
# extra parameters added to the schema
parameters=[
OpenApiParameter(name='artist', description='Filter by artist', required=False, pe=str),
OpenApiParameter(
name='release',
type=OpenApiTypes.DATE,
location=OpenApiParameter.QUERY,
description='Filter by release date',
examples=[
OpenApiExample(
'Example 1',
summary='short optional summary',
description='longer description',
value='1993-08-23'
),
...
],
),
],
# override default docstring extraction
description='More descriptive text',
# provide Authentication class that deviates from the views default
auth=None,
# change the auto-generated operation name
operation_id=None,
# or even completely override what AutoSchema would generate. Provide raw Open API spec Dict.
operation=None,
# attach request/response examples to the operation.
examples=[
OpenApiExample(
'Example 1',
description='longer description',
value=...
),
...
],
)
def list(self, request):
# your non-standard behavior
return super().list(request)
@extend_schema(
request=AlbumLikeSerializer,
responses={204: None},
methods=["POST"]
)
@extend_schema(description='Override a specific method', methods=["GET"])
@action(detail=True, methods=['post', 'get'])
def set_password(self, request, pk=None):
# your action behavior
...In the Python backend ecosystem, there is a major frameworks Django.
Above example code is demonstrating the way to generate the Swagger document in the Django framework with DRF-Speculator. As you can see, it is horrible like Spring RestDocs and Php Laravel cases. Human must write the most of Swagger document parts manually by their hands. If human takes some mistake, it will break the AI agent.
Therefore, DJango is not suitable for new AI era.
Compiler Driven Development
TypeScript Class
TypeScript Source Code
import { ILlmApplication } from "@samchon/openapi";
import typia from "typia";
import { BbsArticleService } from "./BbsArticleService";
const app: ILlmApplication<"chatgpt"> = typia.llm.application<
BbsArticleService,
"chatgpt"
>();
console.log(app);LLM function calling schemas from TypeScript class functions.
The easiest way to build LLM (Large Language Model) function calling schemas type safely without any duplicated code is to use typia.llm.application<Class, Model>() function to a TypeScript class type. The compiler will analyze the target class type (BbsArticleService), and automatically create the LLM function calling schemas.
If you visit above 💻 Playground Link or click the “Compiled JavaScript” tab, you can see how the compiler changes your class type (BbsArticleService) to LLM function calling schemas. LLM function calling schema must be constructed by compiler without any duplicated code like this way. This is the concept “Compiler Driven Development” what I am saying.
Console Output
src/examples/llm.application.violation.ts:4:41 - error TS(typia.llm.application): unsupported type detected
- BbsArticleController.create: unknown
- LLM application's function ("create")'s return type must not be union type with undefined.
- BbsArticleController.erase: unknown
- LLM application's function ("erase")'s parameter must be an object type.
4 const app: ILlmApplication<"chatgpt"> = typia.llm.application<
~~~~~~~~~~~~~~~~~~~~~~
5 BbsArticleController,
~~~~~~~~~~~~~~~~~~~~~~~
6 "chatgpt"
~~~~~~~~~~~
7 >();
~~~
Found 1 error in src/examples/llm.application.violation.ts:4By the way, there’re some restrictions in the typia.llm.application<Class, Model>() function. And the resctrions come from the characteristics of the LLM function calling schema. If you violate some of these restrictions, the typia.llm.application<Class, Model>() function will throw a compilation error with detailed reasons like above.
At first, every function must have only one object typed parameter with static key names. Looking at BbsArticleService.update() or BbsArticleService.erase() functions, you can find that their parameters are capsuled into an object with static key names like input or id. This is the rule of the LLM function calling schema, and called as “keyworded parameters”.
At second, parameters and return types must be primitive types which can be converted to or converted from the JSON. bigint and user defined class types are not allowed. Also, some native classes like Date or Uint8Array are now allowed either.
At last, you have to follow domain restrictions of the target model. For example, Gemini does not allow union types, so if your class has the union type, the typia.llm.application<Class, "gemini">() would be failed with the compilation error. Here is the list of LLM schema types, and you have to follow the domain restrictions of the target model.
IChatGptSchema: OpenAI GPTIClaudeSchema: Anthropic ClaudeIGeminiSchema: Google GeminiILlamaSchema: Meta Llama- Midldle layer schemas
ILlmSchemaV3: middle layer based on OpenAPI v3.0 specificationILlmSchemaV3_1: middle layer based on OpenAPI v3.1 specification
TypeScript NestJS Framework
Controller
import { TypedBody, TypedRoute, TypedParam } from "@nestia/core";
import { Controller } from "@nestjs/common";
import { tags } from "typia";
import { IBbsArticle } from "../../api/structures/bbs/IBbsArticle";
import { IPage } from "../../api/structures/common/IPage";
import { BbsArticleProvider } from "../../providers/bbs/BbsArticleProvider";
@Controller("bbs/articles/:section")
export class BbsArticlesController {
/**
* List up entire articles, but paginated and summarized.
*
* This method is for listing up summarized articles with pagination.
*
* If you want, you can search and sort articles with specific conditions.
*
* @param section Target section
* @param input Pagination request info with searching and sorting options
* @returns Paginated articles with summarization
*/
@TypedRoute.Patch()
public index(
@TypedBody() input: IBbsArticle.IRequest,
): Promise<IPage<IBbsArticle.ISummary>>;
/**
* Get an article with detailed info.
*
* Open an article with detailed info, increasing reading count.
*
* @param section Target section
* @param id Target articles id
* @returns Detailed article info
*/
@TypedRoute.Get(":id")
public at(
@TypedParam("id") id: string,
): Promise<IBbsArticle>;
/**
* Create a new article.
*
* Create a new article and returns its detailed record info.
*
* @param section Target section
* @param input New article info
* @returns Newly created article info
*/
@TypedRoute.Post()
public create(
@TypedBody() input: IBbsArticle.ICreate,
): Promise<IBbsArticle>;
/**
* Update article.
*
* When updating, this BBS system does not overwrite the content, but accumulate it.
* Therefore, whenever an article being updated, length of {@link IBbsArticle.snapshots}
* would be increased and accumulated.
*
* @param id Target articles id
* @param input Content to update
* @returns Newly created content info
*/
@TypedRoute.Put(":id")
public update(
@TypedParam("id") id: string & tags.Format<"uuid">,
@TypedBody() input: IBbsArticle.IUpdate,
): Promise<IBbsArticle.ISnapshot>;
/**
* Erase an article.
*
* Erase an article with specific password.
*
* @param id Target articles id
* @param input Password to erase
*/
@TypedRoute.Delete(":id")
public erase(
@TypedParam("id") id: string,
@TypedBody() input: IBbsArticle.IErase,
): Promise<void>;
}The best framework for AI agent development, if combine with @nestia.
In the TypeScript backend development ecosystem, there is a framework called NestJS. And it is not suitable for AI agent development. It’s because the @nestjs needs triple duplicated code for the DTO schema definition with @nestjs/swagger and class-validator. Furthermore, such duplicated code even cannot be assured safety by the compiler.
However, if combine with its helper library @nestia, it becomes the best framework for AI agent development. @nestia is a helper library for @nestjs, which can generate the Swagger/OpenAPI document by the compiler. No more need to define duplicated schema definitions, so that you can ensure the safety of the API documentation by the compiler.
Just define TypeScript interface based DTO schemas like above. About the controllers, just write description comments on each controller functions. Then @nestia will analyze your TypeScript source files, and generate the Swagger/OpenAPI document by the compiler.
Also, if you’re considering to develop hybrid application that is composed with both human side appliication and AI agent chatbot at the same time, @nestia is also can be the best choice. It will analyze your TypeScript source codes, and generate SDK (Software Development Kit) for frontend developers. With the compiler driven developed SDK, human also can call the API functions safely and conveniently.
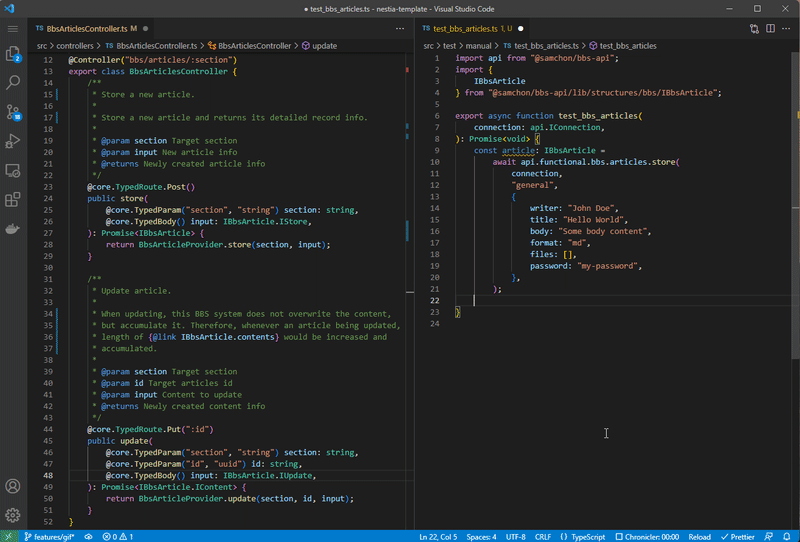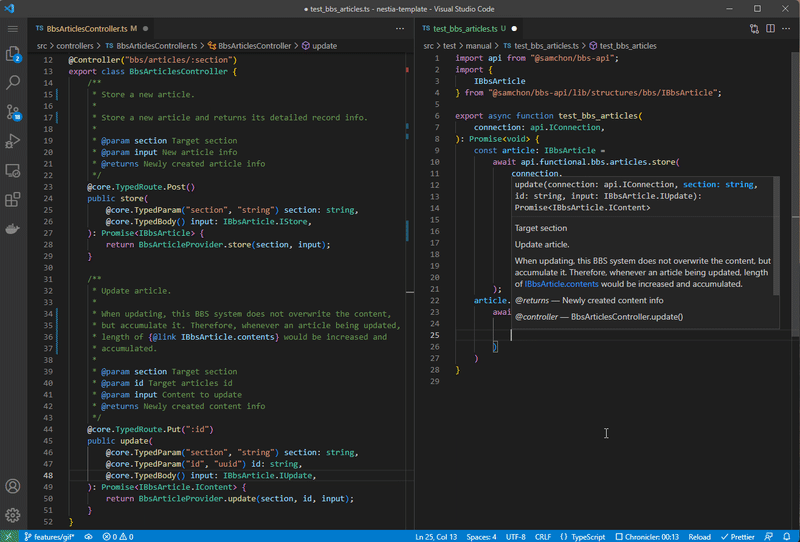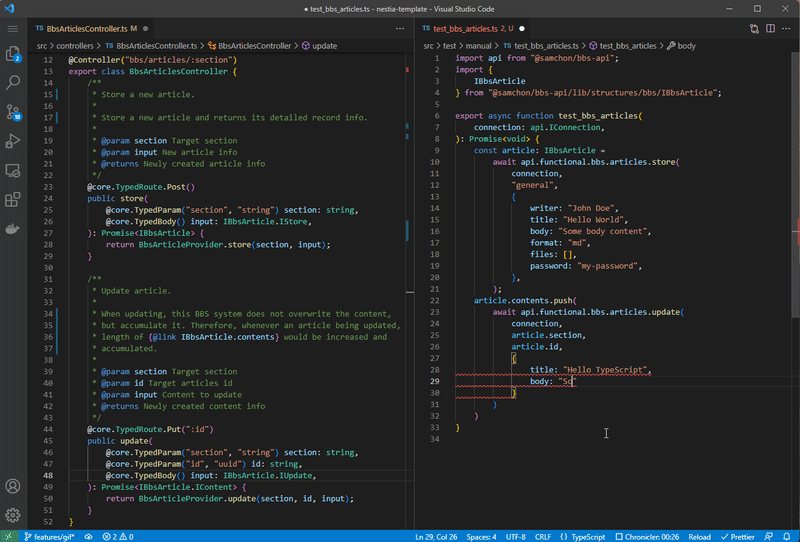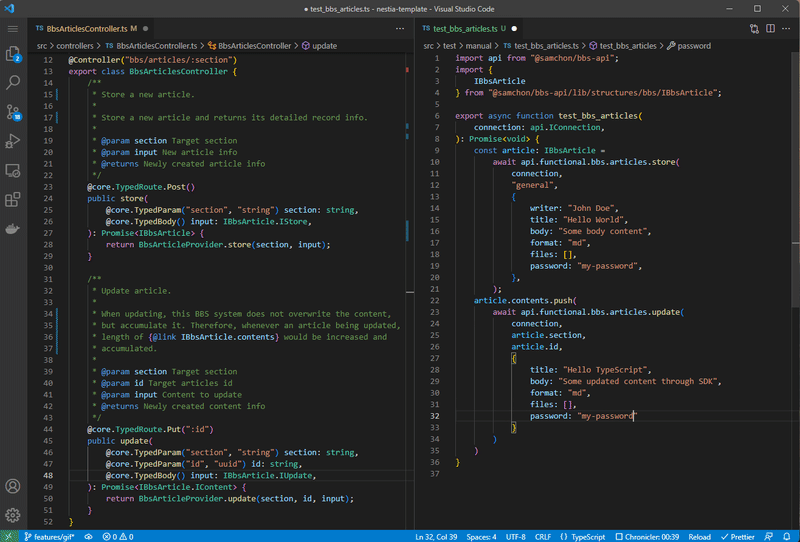
Left is NestJS server code, and right is client (frontend) code utilizing SDK
Python FastAPI Framework
Python FastAPI Framework
class Item(BaseModel):
id: int
name: str
description: str = Field(None, description="The description of the item")
price: float = Field(..., description="The price of the item")
tags: List[str] = Field(
default_factory=list,
description="A list of tags associated with the item"
)
@app.post("/items/")
async def create_item(item: Item):
return itemFastAPI is good framework for AI agent development.
Even though @agentica is a framework for TypeScript developers, it is okay to using another language’s framework for the backend development, unless the framework needs to write the Swagger/OpenAPI document by hand.
In the Python ecosystem, there is another good framework called FastAPI which can build the Swagger/OpenAPI document by the reflection system of the Python language. With the reflection system of Python and FastAPI, you don’t need to write the Swagger/OpenAPI document by hand, and no more need to implement duplicated schema definition either.
Therefore, FastAPI is suitable for the new era’s Agentic AI development. If you know more languages or frameworks which can build the Swagger/OpenAPI document by compiler or reflection like system without duplicated code, please let us know. It may suitable for AI agent development too.
Contract Driven Development
Traditional Way
Hand written swagger.json file first, and then develop applications based on it.
Have you heards of “(OpenAPI) Contract Driven Development”? It is a development methodology that is advocated by OpenAPI Foundation, which created the Swagger/OpenAPI specification. Every developers participating in the project are involved in defining the RestAPI specification together, writing the specification as a Swagger/OpenAPI document hand manually first, and then developing the frontend and backend applications based on it.
Since the specification is clearly defined in advance, it is easy for developers to collaborate with each other and to verify each other’s code. Once the OpenAPI document is written and the specifications are finalized, backend development can also be carried out in parallel by dividing the test program writer and the main program writer, thereby ensuring both productivity and stability.
However, hand writing swagger.json file means that, endless annoying tasks and endless human mistakes would be. In actually, regardless of whether this method is used to develop an AI agent or not, I have never seen a single case of this actually being used around me. No matter how ideal the methodology is, most backend developers are doing code first development, and it is not even ideal.
New Way with Compiler
export interface IBbsArticleService {
/**
* Get all articles.
*
* List up every articles archived in the BBS DB.
*
* @returns List of every articles
*/
index(): IBbsArticle[];
/**
* Create a new article.
*
* Writes a new article and archives it into the DB.
*
* @param props Properties of create function
* @returns Newly created article
*/
create(props: {
/**
* Information of the article to create
*/
input: IBbsArticle.ICreate;
}): IBbsArticle;
/**
* Update an article.
*
* Updates an article with new content.
*
* @param props Properties of update function
* @param input New content to update
*/
update(props: {
/**
* Target article's {@link IBbsArticle.id}.
*/
id: string & tags.Format<"uuid">;
/**
* New content to update.
*/
input: IBbsArticle.IUpdate;
}): void;
/**
* Erase an article.
*
* Erases an article from the DB.
*
* @param props Properties of erase function
*/
erase(props: {
/**
* Target article's {@link IBbsArticle.id}.
*/
id: string & tags.Format<"uuid">;
}): void;
}Contract Driven Development with Compiler.
Considering strengths of the Contract Driven Development, some of them are reasonable and enough acceptable for the new era of AI agent development. Rather than completing all of the functions and then applying them to the AI agent at once, it is more efficient and stable to define the function interface first, and then check whether the AI agent can understand them well through benchmarking before completing the function implementation.
Just define function interface first, with its name, description comments, and DTO (parameters/return) types. If you think that you’ve defined enough detailed descriptions on the function and DTO types, then run the select benchmark features of @agentica/benchmark program only with the interface.
If you’ve get the successful result from the benchmark, then you start the function implementation. If not, then you have to modify the description comments or DTO types, and then run the benchmark program again. This is the new era’s Contract Driven Development with Compiler.
With Selection Benchmark
Selection benchmark is the most important.
Note that, @agentica is a framework specialized in LLM (Large Language Model) function calling, and doing everything with the function calling. And the most important thing in the @agentica based AI chatbot development is, let the AI agent to select proper function to call from the conversation context. It is called function selecting, and the quality of the function selecting would be determined by the quality of the description comments written on each function.
Even if you have completed implementing the TypeScript class or developing the backend, you may not know whether it will work well in the AI agent. Perhaps the description of each function is ambiguous or conflicts with each other, so you may have to modify the already completed program again. Therefore, it is more stable and productive to define the function interface first, and then check whether the AI agent can understand them well through benchmarking before completing the function implementation.
This is the reason why I’m recommending to adapt the new era’s Contract Driven Development with Compiler. Defining interface only, and measuring its performance may look like annoying things. However, I can sure that, this methodology will save your time and effort a lot. You may not suffer from the re-desining and re-implementing the functions after the AI agent development.
Don’t worry about the arguments’ composition step after the function select. @agentica rarely fails to the arguments’ composition step by utilizing the validation feedback strategy. Therefore, just concentrate on the function selecting with the quality of the description comments please.