01 / ai-generated change
AI ships code 10× faster.
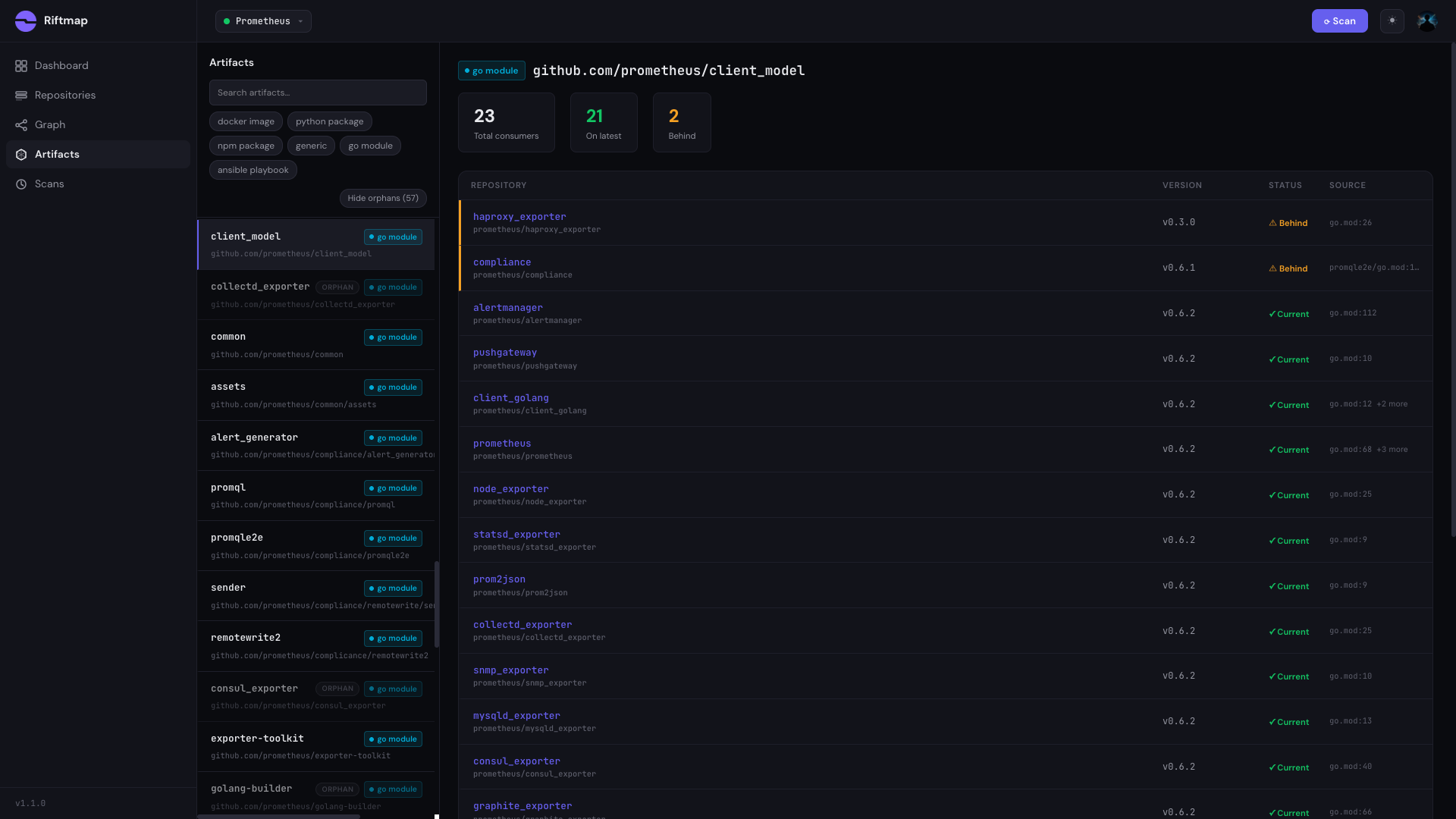
It doesn't know what already exists.
AI accelerates output; it doesn't map what already exists — and three repos referencing the interface it just changed are now silently broken.
compounds every sprint + 312 lines · − 47 lines · 0 edges checked
↳ the same problem, the other direction
Your agents need the graph too. Without it, they reconstruct it on every invocation — at 30× the token cost of a single lookup.
Your agents need the graph too. Without it, they reconstruct it on every invocation — at 30× the token cost of a single lookup.