Latest Blog Posts
Entity Relationship Maps
Posted by Dave Stokes on 2025-06-25 at 13:26
Even the most experienced database professionals are known to feel a little anxious when peering into an unfamiliar database. Hopefully, they inspect to see how the data is normalized and how the various tables are combined to answer complex queries. Entity Relationship Maps (ERM) provide a visual overview of how tables are related and can document the structure of the data.
The Community Edition of DBeaver can provide an ERM easily. First, connect to the database. Right-click on the 'Tables' and then select 'View Diagram'.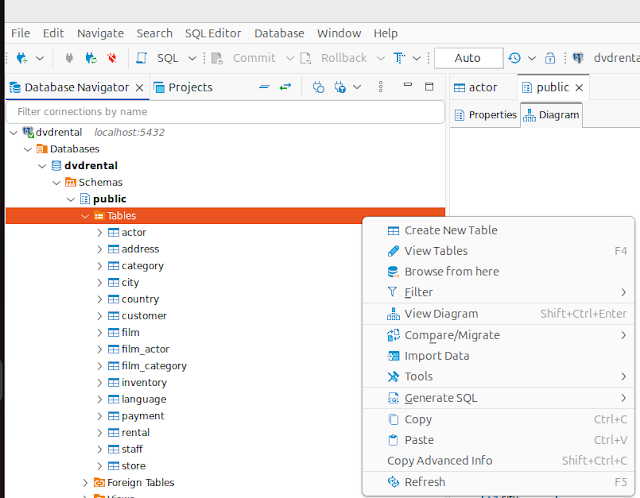
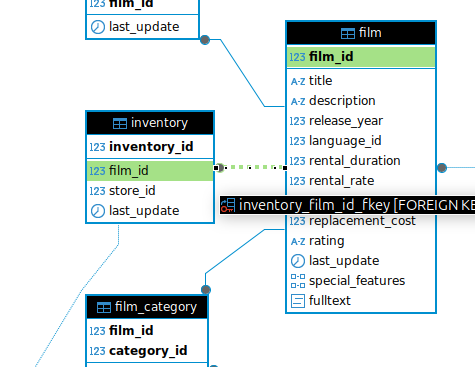
The ERM is then displayed.

And it gets better! If you are not sure how two tables are joined? Click on the link between the tables, and the names of the columns you will want to use in your JOIN statement are highlighted.
Conclusion
Exploring an unfamiliar database can be daunting. But Entity Relationship Maps provide a way to navigate the territory. And Dbeaver is a fantastic tool for working with databases.
CNPG Recipe 20 – Finer Control of Postgres Clusters with Readiness Probes
Posted by Gabriele Bartolini in EDB on 2025-06-25 at 06:04
Explore the new readiness probe introduced in CloudNativePG 1.26, which advances Kubernetes-native lifecycle management for PostgreSQL. Building on the improved probing infrastructure discussed in my previous article, this piece focuses on how readiness probes ensure that only fully synchronised and healthy instances—particularly replicas—are eligible to serve traffic or be promoted to primary. Special emphasis is placed on the streaming probe type and its integration with synchronous replication, giving administrators fine-grained control over failover behaviour and data consistency.
PGConf.EU 2025 - Registration opened
Posted by Magnus Hagander in PostgreSQL Europe on 2025-06-24 at 14:37
The registration for PGConf.EU 2025, which will take place on 21-24 October in Riga, is now open.
We have a limited number of tickets available for purchase with the discount code EARLYBIRD.
This year, the first day of training sessions has been replaced with a Community Events Day. This day has a more limited space, and can be booked as part of the conference registration process or added later, as long as seats last.
We hope you will be able to join us in Riga in October!
Beyond the Basics of Logical Replication
Posted by Radim Marek on 2025-06-24 at 07:10
With First Steps with Logical Replication we set up a basic working replication between a publisher and a subscriber and were introduced to the fundamental concepts. In this article, we're going to expand on the practical aspects of logical replication operational management, monitoring, and dive deep into the foundations of logical decoding.
Initial Data Copy#
As we demonstrated in the first part, when setting up the subscriber, you can choose (or not to) to rely on initial data copy using the option WITH (copy_data = false). While the default copy is incredibly useful behavior, this default has characteristics you should understand before using it in a production environment.
The mechanism effectively asks the publisher to copy the table data by taking a snapshot (courtesy of MVCC), sending it to the subscriber, and thanks to the replication slot "bookmark," seamlessly continues streaming the changes from the point the snapshot was taken.
Simplicity is the key feature here, as a single command handles the snapshot, transfer, and transition to ongoing streaming.
The trade-off you're making is when it comes to performance, solely due to the fact that it's using a single process per table. While it works almost instantly for test tables, you will encounter notable delay and overhead when dealing with tables with gigabytes of data.
Although parallelism can be controlled by the max_sync_workers_per_subscription configuration parameter, it still might leave you waiting for hours (and days) for any real-life database to get replicated. You can monitor whether the tables have already been synchronized or are still waiting/in progress using the pg_subscription_rel catalog.
SELECT srrelid::regclass AS table_name, srsubstate
FROM pg_subscription_rel;
Where each table will have one of the following states:
-
inot yet started -
dcopy is in progress -
ssyncing (or waiting for confirmation) -
rdone & replicating
Luckily, the state r indicates that the s
Contributions for the week of 2025-06-09 (Week 24)
Posted by Cornelia Biacsics in postgres-contrib.org on 2025-06-24 at 06:36
On June, 9th, Andrzej Nowicki held a talk about “From Queries to Pints: Building a Beer Recommendation System with pgvector” at the Malmö PostgreSQL User Group.
On June, 3rd the 5. PostgreSQL User Group NRW MeetUp took place in Germany.
Speakers:
* Josef Machytka about “Boldly Migrate to PostgreSQL - Introducing credativ-pg-migrator" * Mathis Rudolf about "PostgreSQL Locking – Das I in ACID" * Christoph Berg about "Modern VACUUM"
POSETTE: An Event for Postgres 2025 took place June 10-12 online. Organized by:
- Aaron Wislang
- Abe Omorogbe
- Ama Kusi
- Bilge Erdim
- Jeremy Asomaning
- Linda Leste
- Pooja Yarabothu
- Teresa Giacomini
Talk Selection Team: * Claire Giordano * Daniel Gustafsson * Krishnakumar “KK” Ravi * Melanie Plageman
Hosts: * Adam Wolk * Boriss Mejías * Claire Giordano * Derk van Veen * Floor Drees * Melanie Plageman * Thomas Munro
Speakers: * Abe Omorogbe * Adam Wolk * Alexander Kukushkin * Amit Langote * Ashutosh Bapat * Bohan Zhang * Boriss Mejías * Bruce Momjian * Charles Feddersen * Chris Ellis * Cédric Villemain * David Rowley * Derk van Veen * Ellyne Phneah * Gayathri Paderla * Heikki Linnakangas * Jan Karremans * Jelte Fennema-Nio * Jimmy Zelinskie * Johannes Schuetzner * Karen Jex * Krishnakumar “KK” Ravi * Lukas Fittl * Marco Slot * Matt McFarland * Michael John Pena * Nacho Alonso Portillo * Neeta Goel * Nitin Jadhav * Palak Chaturvedi * Pamela Fox * Peter Farkas * Philippe Noël * Polina Bungina * Rahila Syed * Robert Haas * Sandeep Rajeev * Sarah Conway * Sarat Balijapelli * Shinya Kato * Silvano Coriani * Taiob Ali * Tomas Vondra * Varun Dhawan * Vinod Sridharan
Waiting for SQL:202y: Vectors
Posted by Peter Eisentraut in EDB on 2025-06-24 at 04:00
It’s been a while since SQL:2023 was published, and work on the SQL standard continues. Nowadays, everyone in the database field wants vectors, and SQL now has them, too.
(I’m using the term “SQL:202y” for “the next SQL standard after SQL:2023”. I took this naming convention from the C standard, but it’s not an official term for the SQL standard. The current schedule suggests a new release in 2028, but we’ll see.)
Vectors are a popular topic for databases now, related to LLM and “AI” use cases. There is lots of information about this out there; I’m going to keep it simple here and just aim to describe the new SQL features. The basic idea is that you have some relational data in tables, let’s say textual product descriptions, or perhaps images. And then you run this data through … something?, an LLM? — this part is not covered by SQL at the moment — and you get a back vectors. And the idea is that vectors that are mathematically close to each other represent semantically similar data. So where before an application might have searched for “matching” things by just string equality or pattern matching or full-text search, it could now match semantically. Many database management systems have added support for this now, so it makes sense to standardize some of the common parts.
So there is now a new data type in SQL called vector:
CREATE TABLE items (
id int PRIMARY KEY,
somedata varchar,
embedding vector(100, integer)
);
The vector type takes two arguments: A dimension count and a coordinate type. The coordinate type is either an existing numeric type or possibly one of additional implementation-defined keywords. For example, an implementation might choose to support vectors with float16 internal values.
Here is how you could insert data into this type:
INSERT INTO items VALUES (1, 'foo', vector('[1,2,3,4,5,...]', 100, integer));
The vector() constructor takes a serialization of the actual vector data and again a dimension count and a coordinate type.
Again, how you actuall
[...]Suraj Kharage
Posted by Andreas 'ads' Scherbaum on 2025-06-23 at 14:00
PGDay UK 2025 - Registration open
Posted by Dave Page in PGDay UK on 2025-06-23 at 13:45
PGDay UK 2025 will be held in London, England, on Tuesday, September 9, 2025 at the Cavendish Conference Centre.
It features a full day with a track of PostgreSQL presentations from global PostgreSQL experts. It will cover a wide range of topics of interest.
Registration has now opened. Seats are limited so we recommend that you register early if you are interested! There are 20 Early bird discounted tickets available until the 31th of July 2025; grab yours before they run out or the campaign ends.
We will publish the schedule soon.
PGDay.UK is proud to be a PostgreSQL Community Recognised Conference.
We look forward to seeing you in London!
pgstream v0.7.1: JSON transformers, progress tracking and wildcard support for snapshots
Posted by Ahmet Gedemenli in Xata on 2025-06-20 at 11:45
Which PostgreSQL HA Solution Fits Your Needs: Pgpool or Patroni?
Posted by semab tariq in Stormatics on 2025-06-20 at 11:13
When designing a highly available PostgreSQL cluster, two popular tools often come into the conversation: Pgpool-II and Patroni. Both are widely used in production environments, offer solid performance, and aim to improve resilience and reduce downtime; however, they take different approaches to achieving this goal.
We often get questions during webinars/talks and customer calls about which tool is better suited for production deployments. So, we decided to put together this blog to help you understand the differences and guide you in choosing the right solution based on your specific use case.
Before we dive into comparing these two great tools for achieving high availability, let’s first take a quick look at some of the key components involved in building a highly available and resilient setup.
Load Balancing
Load balancing helps distribute incoming SELECT queries evenly across read replicas. By offloading read traffic from the primary node, it can focus on handling write operations more efficiently. Heavy read workloads like reporting queries or dashboards can be directed to standby nodes, reducing the burden on the primary. This can also increase the overall transactions per second (TPS)
Connection Pooling
Connection pooling helps manage database connections efficiently, especially in high-concurrency environments. PostgreSQL has a connection limit per server, and opening/closing connections is expensive. Connection poolers can maintain a pool of persistent connections and reuse them for incoming client requests, which reduces overhead and boosts performance. This is equally important when many clients or applications interact with the database simultaneously.
Auto Failover
Auto failover ensures that when the primary database goes down, another healthy standby is automatically promoted to take its place, minimizing manual intervention. Auto failover is a central component to achieving true high availability and reducing downtime during node failures.
Consensus-Based Voti
[...]The differences between OrioleDB and Neon
Posted by Alexander Korotkov on 2025-06-20 at 00:00
In a recent Hacker News discussion, there was some confusion about the differences between OrioleDB and Neon. Both look alike at first glance. Both promise a "next‑gen Postgres". Both have support for cloud‑native storage.
This post explains how the two projects differ in practice. And importantly, OrioleDB is more than an undo log for PostgreSQL.
The Core Differences
OrioleDB
OrioleDB is a Postgres extension. It implements a Table Access Method to replace the default storage method (Heap), providing the following key features:
- MVCC based on UNDO, which prevents bloat as much as possible;
- IO-friendly copy‑on‑write checkpoints with very compact row‑level WAL;
- An effective shared memory caching layer based on squizzled pointers.
Neon
Neon uses the default Table Access Method (Heap) and replaces the storage layer. The WAL is written to the safekeepers, and blocks are read from page servers backed by object storage, providing instant branching and scale-to-zero capabilities.
Architecture comparison
CPU Scalability
OrioleDB eliminates scalability bottlenecks in the PostgreSQL buffer manager and WAL writer by introducing a new shared memory caching layer based on squizzled pointers and row-level write-ahead logging (WAL). Therefore, OrioleDB can handle a high-intensity read-write workload on large virtual machines.
Neon compute nodes have roughly the same scalability as stock PostgreSQL. Still, Neon allows for the instant addition of more read-only compute nodes connected to the same multi-tenant storage.
IO Scalability
OrioleDB implements copy-on-write checkpoints, which improve locality of writes. Also, OrioleDB’s row-level WAL saves write IOPS due to its smaller volume.
Neon implements a distributed network storage layer that can potentially scale to infinity. The drawback is network latency, which could be very significant in contrast with fast local NVMe.
VACUUM & Data bloat
OrioleDB implements block-level and row-level UNDO log
[...]PostgreSQL Hacking + Patch Review Workshops for July 2025
Posted by Robert Haas in EDB on 2025-06-19 at 18:01
PostgreSQL active-active replication, do you really need it?
Posted by Jan Wieremjewicz in Percona on 2025-06-18 at 00:00
PostgreSQL active-active replication, do you really need it?
Before we start, what is active-active?
Active-active, also referred to as multi-primary, is a setup where multiple database nodes can accept writes at the same time and propagate those changes to the others. In comparison, regular streaming replication in PostgreSQL allows only one node (the primary) to accept writes. All other nodes (replicas) are read-only and follow changes.
In an active-active setup:
CNPG Recipe 19 – Finer Control Over Postgres Startup with Probes
Posted by Gabriele Bartolini in EDB on 2025-06-17 at 10:17
CloudNativePG 1.26 introduces enhanced support for Kubernetes startup probes, giving users finer control over how and when PostgreSQL instances are marked as “started.” This article explores the new capabilities, including both basic and advanced configuration modes, and explains the different probe strategies—such as pg_isready, SQL query, and streaming for replicas. It provides practical guidance for improving the reliability of high-availability Postgres clusters by aligning startup conditions with actual database readiness.
Preserve optimizer statistics during major upgrades with PostgreSQL v18
Posted by Laurenz Albe in Cybertec on 2025-06-17 at 09:07

© Laurenz Albe 2025
Everybody wants good performance. When it comes to the execution of SQL statements, accurate optimizer statistics are key. With the upcoming v18 release, PostgreSQL will preserve the optimizer statistics during an upgrade with dump/restore or pg_upgrade (see commit 1fd1bd8710 and following). With the beta testing season for PostgreSQL v18 opened, it is time to get acquainted with the new feature.
A word about statistics
First, let's clear up a frequent source of confusion. We use the word “statistics” for two quite different things in PostgreSQL:
- Information about the activities of the database: PostgreSQL gathers these monitoring data in shared memory and persists them across restarts in the
pg_statdirectory. You can access these data through thepg_stat_*views. - Information about the content and distribution of the data in the user tables:
ANALYZEgathers these data and stores them in the catalog tablespg_class,pg_statisticandpg_statistic_ext_data. These data allow the query planner to estimate the cost and result row count of query execution plans and allow PostgreSQL to find the best execution plan.
I'll talk about the latter kind of statistics here, and I call them “optimizer statistics” (as opposed to “monitoring statistics”).
Upgrade and optimizer statistics before PostgreSQL v18
Before PostgreSQL v18, there was no way to preserve optimizer statistics across a (major) upgrade. That was no big problem if you upgraded using pg_dumpall — loading the dump will automatically trigger autoanalyze. Waiting for the statistics collection to finish constitutes a additional delay until the database is ready for use. However, dump/restore is slow enough that that additional delay doesn't really matter much. At least you need no manual intervention to gather the statistics!
The situation with pg_upgrade was considerably worse. pg_upgrade dumps and restores only the metadata from the catalog tables and leaves the data files unchanged. pg_upgrade doesn
SELECT FOR UPDATE considered harmful in PostgreSQL
Posted by Laurenz Albe in Cybertec on 2025-06-17 at 06:00
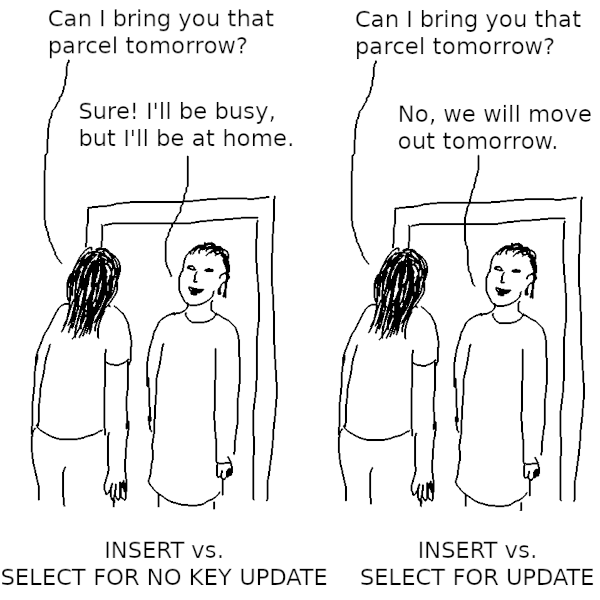
© Laurenz Albe 2025
Recently, while investigating a deadlock for a customer, I was again reminded how harmful SELECT FOR UPDATE can be for database concurrency. This is nothing new, but I find that many people don't know about the PostgreSQL row lock modes. So here I'll write up a detailed explanation to let you know when to avoid SELECT FOR UPDATE.
The motivation behind SELECT FOR UPDATE: avoiding lost updates
Data modifying statements like UPDATE or DELETE lock the rows they process to prevent concurrent data modifications. However, this is often too late. With the default isolation level READ COMMITTED, there is a race condition: a concurrent transaction can modify a row between the time you read it and the time you update it. In that case, you obliterate the effects of that concurrent data modification. This transaction anomaly is known as “lost update”.
If you don't want to use a higher transaction isolation level (and deal with potential serialization errors), you can avoid the race condition by locking the row as you read it:
START TRANSACTION; /* lock the row against concurrent modifications */ SELECT data FROM tab WHERE key = 42 FOR UPDATE; /* computation */ /* update the row with new data */ UPDATE tab SET data = 'new' WHERE key = 42; COMMIT;
But attention! The above code is wrong! To understand why, we have to dig a little deeper.
How PostgreSQL uses locks to maintain foreign key consistency
We need to understand how PostgreSQL guarantees referential integrity. Let's consider the following tables:
CREATE TABLE parent ( p_id bigint PRIMARY KEY, p_val integer NOT NULL ); INSERT INTO parent VALUES (1, 42); CREATE TABLE child ( c_id bigint PRIMARY KEY, p_id bigint REFERENCES parent );
Let's start a transaction and insert a new row in child that references the existing row in parent:
START TRANSACTION; INSERT INTO child VALUES (100, 1);
At this point, the new row is not yet visible to concurrent transactions, because we didn't yet commit the trans
[...]Avoiding Timezone Traps: Correctly Extracting Date/Time Subfields in Django with PostgreSQL
Posted by Colin Copeland on 2025-06-16 at 19:00
Working with timezones can sometimes lead to confusing results, especially when combining Django's ORM, raw SQL for performance (like in PostgreSQL materialized views), and specific timezone requirements. I recently had an issue while aggregating traffic stop data by year, where all yearly calculations needed to reflect the 'America/New_York' (EST/EDT) timezone, even though our original data contained timestamp with time zone fields. We were using django-pgviews-redux to manage materialized views, and I mistakenly attempted to apply timezone logic to a date field that had no time or timezone information.
The core issue stemmed from a misunderstanding of how PostgreSQL handles EXTRACT operations on date types when combined with AT TIME ZONE, especially within a Django environment that defaults database connections to UTC.
PostgreSQL's Handling of Timestamps and Timezones
PostgreSQL's timestamp with time zone (often abbreviated as timestamptz) type is a common database type for storing date and time information. As per the PostgreSQL documentation:
For timestamp with time zone values, an input string that includes an explicit time zone will be converted to UTC (Universal Coordinated Time) using the appropriate offset for that time zone.
When you query a timestamptz column, PostgreSQL converts the stored UTC value back to the current session's TimeZone. You can see your session's timezone with SHOW TIME ZONE;. Django, by default, sets this session TimeZone to 'UTC' for all database connections. This is a sensible default for consistency but can be a source of confusion if you're also interacting with the database via psql or other clients that might use your system's local timezone (e.g., 'America/New_York' on my Mac via Postgres.app).
You can change the session timezone and observe its effect:
tztest=# SHOW TIME ZONE;
-- TimeZone
-- ------------------
-- America/New_York (If running from my MacNisha Moond
Posted by Andreas 'ads' Scherbaum on 2025-06-16 at 14:00
PgPedia Week, 2025-06-15
Posted by Ian Barwick on 2025-06-16 at 10:25
Handling BLOBs In PostgreSQL Part 2
Posted by Stefanie Janine on 2025-06-15 at 22:00
BLOBs In PostgreSQL
Previous Blog Post
I have already published a blog post about PostgreSQL blobs.
But due to someone posting to get help about another implementation on the PostgreSQL Chat Telegram group about a very unusual method to store blobs, I thought, that should now also be covered.
I did not cover that method, because it is one of the worst ideas to handle blobs inside PostgreSQL.
How It Started
Someone was migrating data from Oracle to PostgreSQL and had blobs exceeding the limit BYTEA of max 1 GB of data.
They used a method that he described as writing BLOBS to OIDs. Which is obviously not what he realy did, ad OID is a numerical data type.
What They Used
In fact they used lo. That is storing a blob in a table where the binary data is stored as TOAST in the file system where PostgreSQL is located and an OID points to the TOASTed data.
Handling By PostgreSQL
With this method it is possible to store bigger binary files than the 1 GB limit of BYTEA.
But that does also add a lot of overhead to handling the blob data. The client can only handle the complete blob data. All layers in between have to handle the data, the PostgreSQL instance to get the data by pointers from disk, using the memory to load the binary data, and client side for example ODBC or JDBC.
Deleting Lo BLOBs
Also deleting these binaray objects does have downsides, too. Deleting rows or truncating a table does not delete the blob data, it leaves orphaned blob data.
One has to take care of orphaned blob data, that is not referenced anymore in the table pg_largeobject_metadata have to be removed with another job, vacuumlo.
That causes additional disk traffic, of course.
Comparing To File Systems Deletions
Compare that to the easyness of getting a file location from the database and the content from disk. Including deleting files is much easier and does not impact the database perfomrance.
Backups
The large objects are also part of the database backups. They are b
[...]Contributions for the week of 2025-06-02 (Week 23)
Posted by Boriss Mejias in postgres-contrib.org on 2025-06-12 at 11:12
PG Day France 2025 took place on June 3 and 4 in Mons, Belgium, organized by Leila Bakkali, Matt Cornillon, Stefan Fercot, Flavio Gurgel, Anthony Nowocien, and Julien Riou, with the help of Jean-Paul Argudo, Laetitia Avrot, Sylvain Beorchia, Damien Clochard, Yves Collin, Bertrand Drouvot, Cédric Duprez, Maxime Longuet, Helene Nguyen, and Anaïs Oberto as volunteers.
Speakers:
First steps with Logical Replication in PostgreSQL
Posted by Radim Marek on 2025-06-11 at 00:00
Most applications start with a single PostgreSQL database, but over time, the need to scale out, distribute the load, or integrate naturally arises. PostgreSQL's logical replication is one of the features that meets these demands by streaming row-level changes from one PostgreSQL instance to another, all using a publish-subscribe model. Logical replication is more than an advanced feature; it provides a flexible framework you can build on to further distribute and integrate PostgreSQL within your architecture.
In this article, we will start with the foundation, explore the core ideas behind logical replication, and learn how to use it.
Physical vs. Logical Replication#
Before we can dive deeper, let's understand the role of replication in PostgreSQL and how it's built on top of the Write-Ahead Log (WAL).
The WAL is a sequential, append-only log that records every change made to the cluster data. For durability purposes, all modifications are first written to the WAL and only then permanently written to disk. This allows PostgreSQL to recover from crashes by replaying logged changes.
Versioned changes, necessitated by concurrent transactions, are managed through Multi-Version Concurrency Control (MVCC). Instead of overwriting data directly, MVCC creates multiple versions of rows, allowing each transaction to see a consistent snapshot of the database. It is the WAL that captures these versioned changes along with the transactional metadata to ensure data consistency at any given point in time.
Physical replication is built directly on the Write-Ahead Log. It enables streaming of the binary WAL data from the primary server to one or more standby servers (replicas), effectively creating a byte-for-byte copy of the entire cluster. This requirement makes the replicas read-only, making them ideal candidates for failover or scaling purposes.
Compared to this, Logical replication, while also being built on top of the WAL data, takes a fundamentally different approach. Instead of streaming ra
[...]Checklist: Is Your PostgreSQL Deployment Production-Grade?
Posted by Umair Shahid in Stormatics on 2025-06-10 at 14:00
PgPedia Week, 2025-06-08
Posted by Ian Barwick on 2025-06-10 at 10:11
Of note:
new GUC log_lock_failure renamed to log_lock_failures commit e5a3c9d9 (" postgres_fdw: Inherit the local transaction's access/deferrable modes. ") was reverted PostgreSQL 18 articles What's New in PostgreSQL 18 - a DBA's Perspective (2025-05-23) - TianzhouUsing regular expressions and arrays in PostgreSQL
Posted by Hans-Juergen Schoenig in Cybertec on 2025-06-10 at 08:00
Regular expressions and PostgreSQL have been a great team for many many years. The same is true for PostgreSQL arrays, which have been around for a long time as well. However, what people rarely do is combine those two technologies into something more powerful that can be used for various purposes.
Using ANY and ALL
One of the most widely adopted ways of dealing with arrays is the idea of ANY and ALL, which has been supported by PostgreSQL since God knows when. Those two keywords allow us to figure out if a certain value and an array are a match.
Here are some examples:
```sql
test=# SELECT array_agg(x) FROM generate_series(1, 5) AS x;
array_agg
-------------
{1,2,3,4,5}
(1 row)
test=# SELECT 3 = ANY(array_agg(x))
FROM generate_series(1, 5) AS x;
?column?
----------
t
(1 row)
test=# SELECT 3 = ALL(array_agg(x))
FROM generate_series(1, 5) AS x;
?column?
----------
f
(1 row)
```
The first statement simply generates an array of numbers, which can be used in my example to demonstrate how ANY and ALL work. The idea is simple: ANY will check if one of the values in the array matches - ALL will check if all of the values are a match. So far this is quite common.
However, what happens if we try to apply this concept to regular expressions?
PostgreSQL and regular expressions
Many readers might be surprised to learn that combining those two techniques is indeed possible and actually fairly straight forward. Note that in the example above ANY and ALL were essentially used in combination with the = operator. However, we can also apply the ~ operator, which is the PostgreSQL way of handling regular expressions:
```sql test=# SELECT 'my fancy string' ~ '.*ancy.*ri.+$'; ?column? ---------- t (1 row) ```
What it essentially does is matching the regular expression on the right hand side of the operator with the string on the left. So far so good, but what happens if we expand on this a bit?
Here is what we can do:
```sql test=# SELECT array_agg(exp)[...]
pgsql_tweaks 0.11.3 Released
Posted by Stefanie Janine on 2025-06-09 at 22:00
pgsql_tweaks is a bundle of functions and views for PostgreSQL
The source code is available on GitLab, a mirror is hosted on GitHub.
One could install the whole package, or just copy what is needed from the source code.
The extension is also available on PGXN.
General changes
PostgreSQL 18 Support
No code has been changed. Tests against PostgreSQL 18 beta 1 have been unsuccessful.
Therefore PostgreSQL 18 is now supoorted by pgsql_tweaks.
The reason it took some time to test against the upcoming version is that there have been some problems with the Docker containers, to have them running PostgreSQL 18 as there have been changes, that made it a bit hard to get that version running.
I execute the tests always against Docker containers.
Teresa Lopes
Posted by Andreas 'ads' Scherbaum on 2025-06-09 at 14:00
PGConf.EU 2025 - Call for Presentations
Posted by Magnus Hagander in PostgreSQL Europe on 2025-06-09 at 13:04
The Call for Presentations for PostgreSQL Conference Europe that will take place in Riga, Latvia from October 21 to 24 is now open.
Key dates
- Submission deadline: 30 June (at midnight, local time Riga, Latvia; GMT+3)
- Speakers notified: before 1 August
- Conference: 21-24 October
To submit your proposals and for more information see our website. Speakers can submit up to three (3) proposed talks each.
Session format
There will be a mix of shorter (25 min) and longer (45 min) sessions, which will be held in English. They may be on any topic related to PostgreSQL.
Selection process
The proposals will be considered by committee who will produce a schedule to be published nearer the conference date. The members of the talk selection committee will be listed soon on the conference website.
For more details about sponsoring the event, see the website.
For any questions, contact us at [email protected].
CORE Database Schema Design: Constraint-driven, Optimized, Responsive, and Efficient
Posted by Andrew Atkinson on 2025-06-09 at 00:00
Introduction
In this post, we’ll cover some database design principles and package them up into a catchy mnemonic acronym.
Software engineering is loaded with acronyms like this. For example, SOLID principles describe 5 principles, Single responsibility, Open-closed, Liskov substitution, Interface segregation and Dependency inversion, that promote good object-oriented design.
Databases are loaded with acronyms, for example “ACID” for the properties of a transaction, but I wasn’t familiar with one the schema designer could keep in mind while they’re working.
Thus, the motivation for this acronym was to help the schema designer, by packaging up some principles of good design practices for database schema design. It’s not based in research or academia though, so don’t take this too seriously. That said, I’d love your feedback!
Let’s get into it.
Picking a mnemonic acronym
In picking an acronym, I wanted it to be short and have each letter describe a word that’s useful, practical, and grounded in experience. I preferred a real word for memorability!
The result was “CORE.” Let’s explore each letter and the word behind it.
Constraint-Driven
The first word (technically two) is “constraint-driven.” Relational databases offer rigid structures, but the ability to be changed while online, a form of flexibility in their evolution. We evolve their structure through DDL. They use data types and constraints changes, as new entities and relationships are added.
Constraint-driven refers to leveraging all the constraint objects available, designing for our needs today, but also in a more general sense to apply restrictions to designs in the pursue of data consistency and quality.
Let’s look at some examples. Choose the appropriate data types, like a numeric data type and not a character data type when storing a number. Use NOT NULL for columns by default. Create foreign key constraints for table relationships by default.
Validate expected data inputs using check constraints. F
[...]Understanding High Water Mark Locking Issues in PostgreSQL Vacuums
Posted by Shane Borden on 2025-06-06 at 20:49
I recently had a customer that wanted to leverage read replicas to ensure that their read queries were not going to impeded with work being done on the primary instance and also required an SLA of at worst a few seconds. Ultimately they weren’t meeting the SLA and my colleagues and I were asked to look at what was going on.

The first thing we came to understand is that the pattern of work on the primary is a somewhat frequent large DELETE statement followed by a data refresh accomplished by a COPY from STDIN command against a partitioned table with 16 hash partitions.
The problem being observed was that periodically the SELECTs occurring on the read replica would time out and not meet the SLA. Upon investigation, we found that the “startup” process on the read replica would periodically request an “exclusive lock” on some random partition. This exclusive lock would block the SELECT (which is partition unaware) and then cause the timeout. But what is causing the timeout?
After spending some time investigating, the team was able to correlate the exclusive lock with a routine “autovacuum” occurring on the primary. But why was it locking? After inspection of the WAL, it turns out that it the issue was due to a step in the vacuum process whereby it tries to return free pages at the end of the table back to the OS, truncation of the High Water Mark (HWM). Essentially the lock is requested on the primary and then transmitted to the replica via the WAL so that the tables can be kept consistent.
To confirm that it was in fact the step in VACUUM that truncates the HWM, we decided to alter each partition of the table to allow VACUUM to skip that step:
ALTER TABLE [table name / partition name] SET (vacuum_truncate = false);
After letting this run for 24 hours, we in fact saw no further blocking locks causing SLA misses on the replicas. Should we worry about shrinking the High Water Mark (HWM)? Well as with everything in IT, it depends. Other DBMS engines like Oracle do not shrink the
[...]Top posters
Number of posts in the past two months
 Ian Barwick - 8
Ian Barwick - 8- David Wheeler (Tembo) - 8
- Andreas 'ads' Scherbaum - 6
- Andrew Atkinson - 5
- Henrietta Dombrovskaya - 4
- Andreas Scherbaum - 4
- Tomas Vondra - 4
- Umair Shahid (Stormatics) - 4
- semab tariq (Stormatics) - 4
- Laurenz Albe (Cybertec) - 4
Top teams
Number of posts in the past two months
- Cybertec - 10
- Stormatics - 9
- Xata - 8
- EDB - 8
- Tembo - 8
- postgres-contrib.org - 6
- Crunchy Data - 4
- Hornetlabs Technology - 3
- Percona - 3
- PostGIS - 3
Feeds
Planet
- Policy for being listed on Planet PostgreSQL.
- Add your blog to Planet PostgreSQL.
- List of all subscribed blogs.
- Manage your registration.
Contact
Get in touch with the Planet PostgreSQL administrators at planet at postgresql.org.