





If you’ve heard the phrase ‘coding is dead’ for a mind-numbingly high number of times, take a deep breath and pause. A new benchmark from researchers across notable universities in the United States and Canada has sparked a twist in the tale.
It turns out that AI is far from solving some of the most complex coding problems today.
A study by New York University, Princeton University, the University of California, San Diego, McGill University, and others indicates a significant gap between the coding capabilities of present-day LLMs and elite human intelligence.
LLMs Struggle to Use Novel Insights for Problem Solving
The researchers began by stating the shortcomings of the benchmarks available today. For instance, the LiveCodeBench evaluation suffers from “inconsistent environments, weak test cases vulnerable to false positives, unbalanced difficulty distributions, and the inability to isolate the effects of search contamination”.
They added that other benchmarks, like SWE-Bench, test the models on code maintenance rather than algorithmic design.
Other benchmarks, like CodeELO, do introduce competitive programming problems. Still, their reliance on static and archaic issues makes it difficult to check if models are retrieving solutions based on reasoning or memory.
To alleviate such concerns, the researchers introduced LiveCodeBench Pro, an evaluation benchmark for coding designed to avoid data contamination. The models were evaluated with 584 problems sourced directly from ‘world-class contests’ before solutions or discussions were available.
Additionally, a team of Olympiad medalists annotates each problem in the benchmark to categorise it based on its difficulty level and nature—whether it is knowledge-heavy, observation-heavy, or logic-heavy.
Sadly, none of these models solved a single problem in the ‘Hard’ category. Even the best and latest models from OpenAI, Google, Anthropic, and others that were evaluated scored 0%.
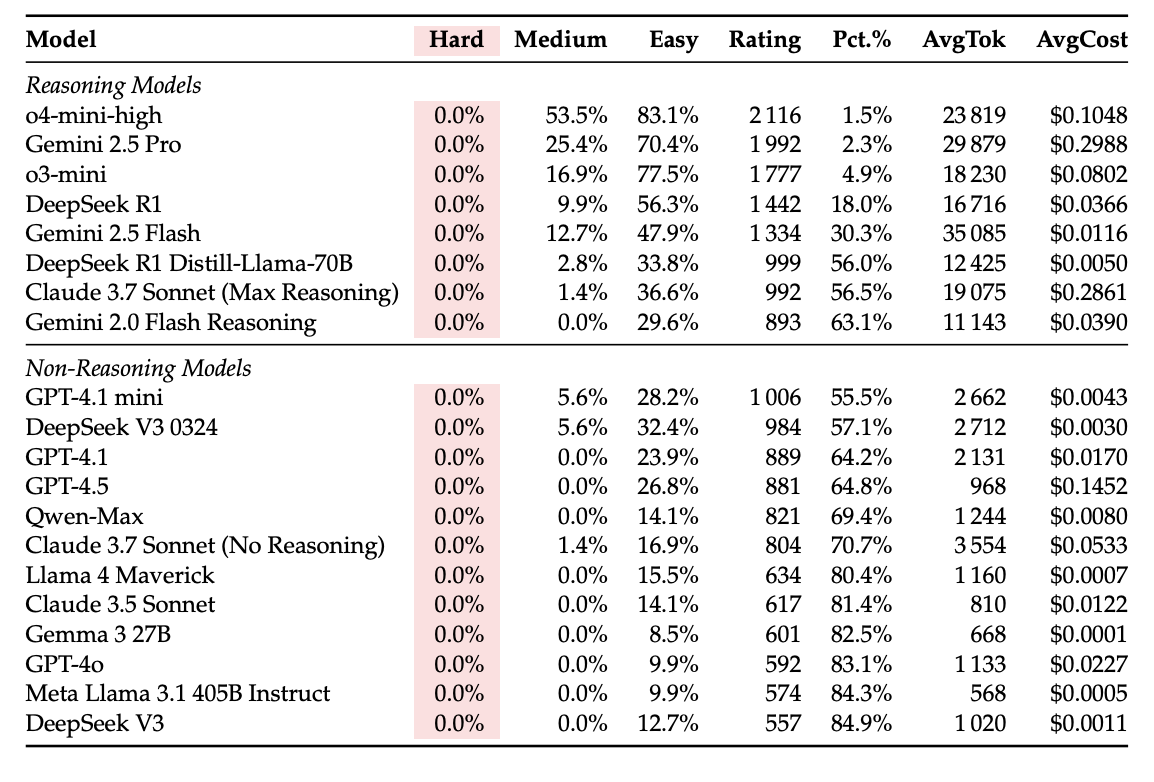
In the ‘Medium’ difficulty category, OpenAI’s o4-mini-high model scored the highest at 53.5%.
AI models performed better on knowledge-heavy problems—ones that can be solved by stitching well-known templates, as the requisite problem-solving patterns appear ‘verbatim in training data’. Even on logic-heavy problems, which require a patterned way of thinking, these models performed well.
However, they performed poorly on observation-heavy problems, whose solutions hinge on the discovery of novel insights — “something that cannot be retrieved from memorised snippets alone”.
When these researchers diagnosed the failure modes of these models, the largest one was where these models committed errors regarding the algorithms. “These are genuine conceptual slips, instead of surface bugs,” said the authors.
“LLMs frequently fail even on provided sample inputs, suggesting incomplete utilisation of given information and indicating room for improvement even in simple settings,” added the authors. They also said that these models show a substantial improvement in overall performance with multiple attempts to solve the problems.
They concluded that these models solve problems involving the implementation of techniques, frameworks, and patterns but struggle to solve ones involving complex reasoning, nuances, and edge cases.
“Despite claims of surpassing elite humans, a significant gap still remains, particularly in areas demanding novel insights,” they added.
For detailed information, comparisons, scores, and evaluation mechanisms, check out the technical report’s PDF here.
This, however, is one of the many reports that highlight the shortcomings of AI-enabled coding, despite the optimism expressed by several tech leaders worldwide.
You Can’t Code for a Long Time With AI
Recently, an Oxford researcher, Toby Ord, proposed that AI agents might have a “half-life” when performing a task.
This was in relation to another research from METR (Model Evaluation & Threat Research), which showed that the capacity of AI agents to handle longer tasks doubled every seven months.
They measured that the doubling time for an 80% success rate is 213 days, and for 50%, it is 212 days, establishing consistency in their findings.
When Ord analysed the research, he discovered that, just like radioactive decay, the AI agent’s success rate followed an exponential decline.
For instance, if an AI model could complete a one-hour task with 50% success, it only had a 25% chance of successfully completing a two-hour task. This indicates that for 99% reliability, task duration must be reduced by a factor of 70.
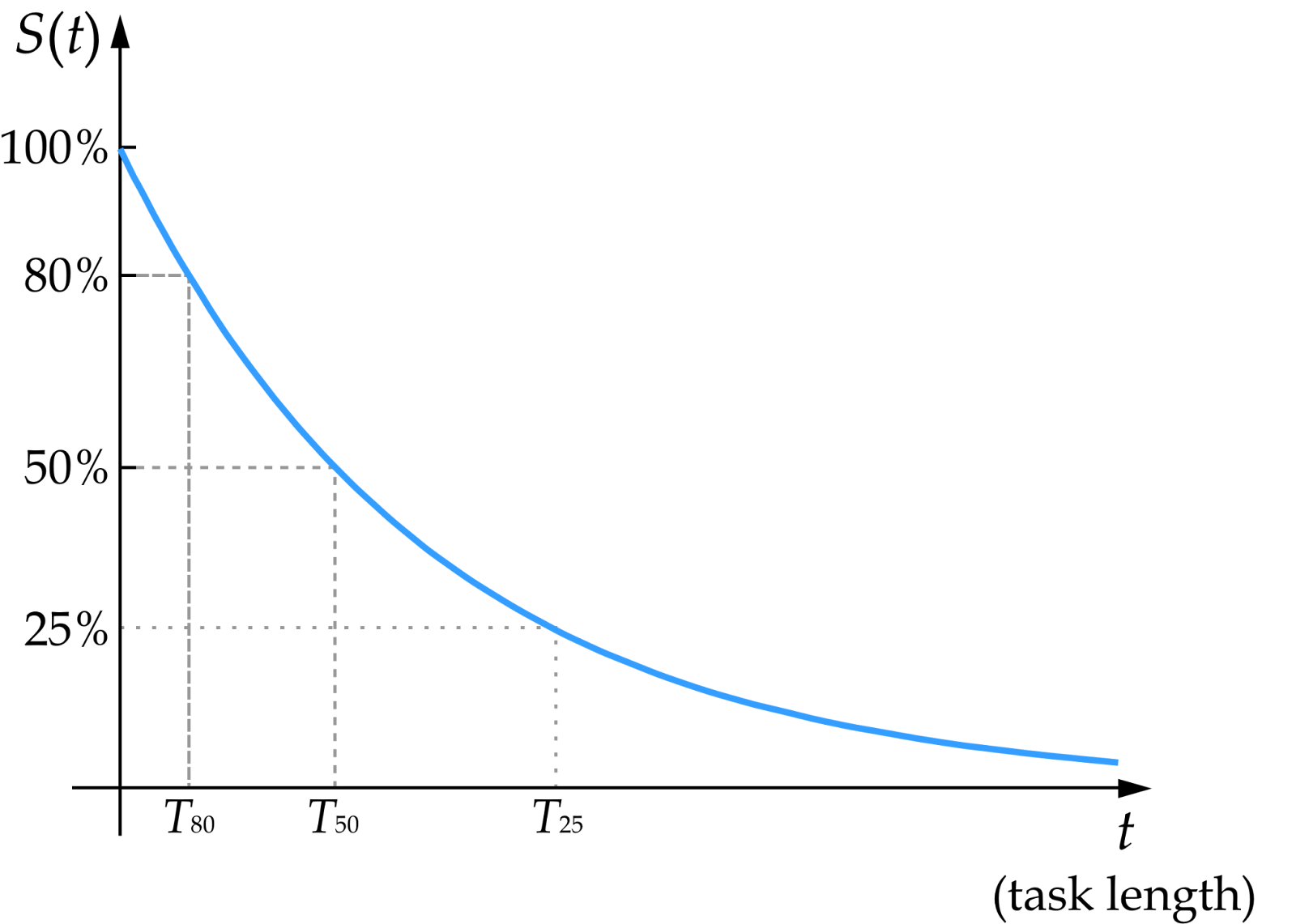
Source: Toby Ord
However, Ord observed a time gap between the 50% success rate time horizon and the 80% success rate time horizon.
“For the best model (Claude 3.7 Sonnet), it could achieve a 50% success rate on tasks up to 59 minutes vs only 15 minutes if an 80% success rate was required,” said Ord.
“If those results generalise to the other models, then we could also see it like this: the task length for an 80% success rate is 1/4 the task length for a 50% success rate. Or in terms of improvement: what is doable with a 50% success rate now is doable with an 80% success rate in 14 months’ time (= 2 doubling times),” he added.
Although METR indicates that AI agents can tackle longer tasks every 7 months, Ord’s analysis shows that high-reliability performance still demands significantly shorter task durations.
This means the timeline for AI to handle complex coding projects remains unclear, despite steady improvements in capability.
















